Machine Learning FAQ
Why do prompt templates matter so much during instruction finetuning?
Prompt templates matter during instruction finetuning because the model is not just learning abstractly to “be helpful.” It is learning a specific token pattern that maps an instruction-formatted input to a preferred response.
That means details such as:
- role markers
- separators
- special tokens
- generation prompts
- the ordering of instruction, input, and response fields
all become part of the learned behavior.
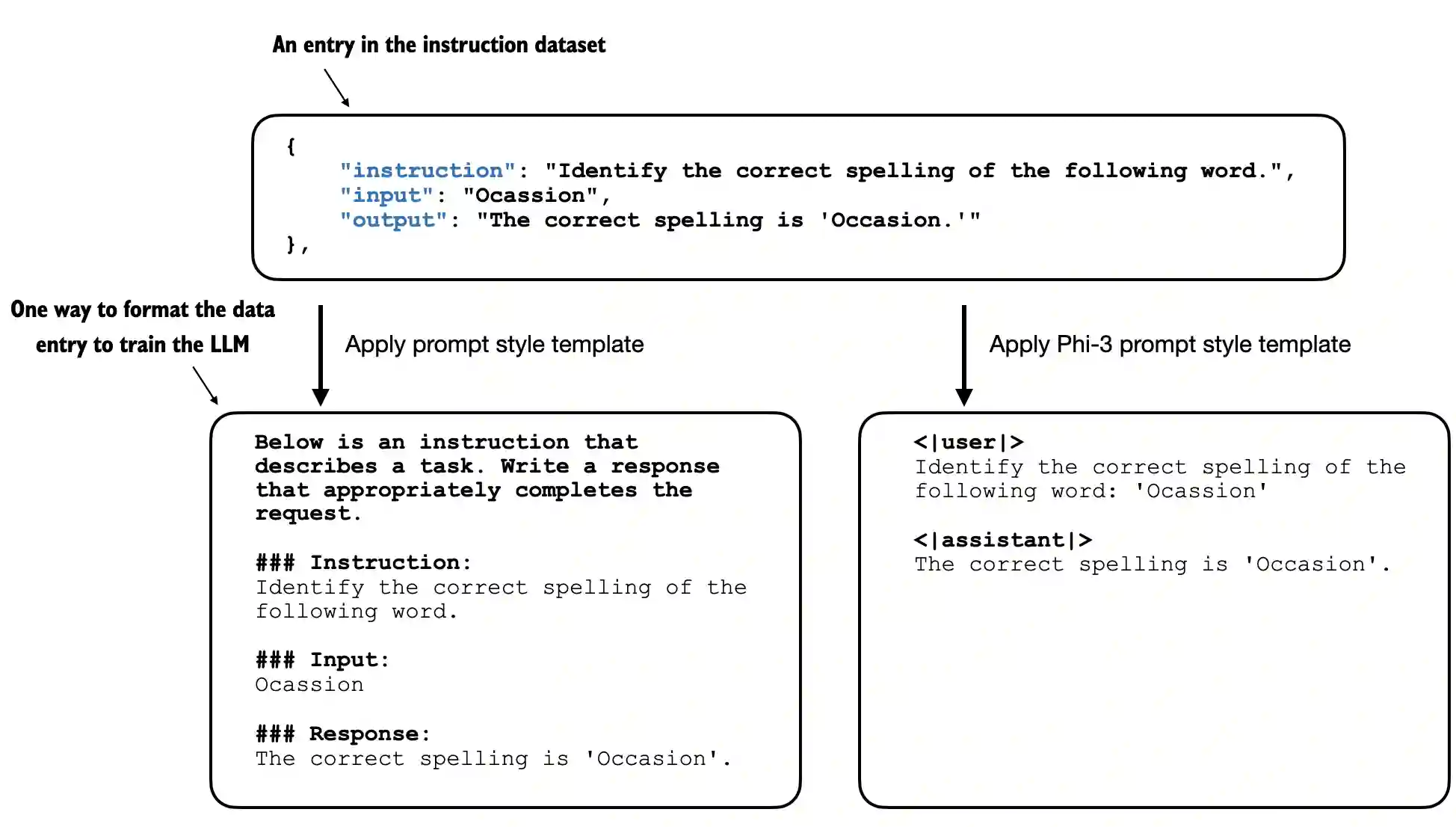
If you train with one template and infer with another, the model may still work somewhat, but behavior often degrades because the token structure no longer matches what it learned during finetuning.
This is especially important for chat-style models. A good chat template does not just decorate the prompt. It tells the model where user input ends, where assistant output begins, and what sort of response pattern should follow.
The repo’s chapter 7 material also shows that prompt-style choices can affect efficiency. A more concise template can sometimes save tokens and make training or inference slightly cheaper without changing the underlying task.
So prompt templates matter because they are part of the training distribution itself, not merely a cosmetic wrapper.
In short, prompt templates matter during instruction finetuning because the model learns a concrete token-level prompt-to-response format, and changing that format at inference time can noticeably weaken the behavior you tuned for.