Machine Learning FAQ
Why do MoE models have huge parameter counts but lower active compute per token?
MoE models have huge total parameter counts because they contain many expert feed-forward modules, but their active compute per token is lower because a router activates only a small subset of those experts for each token.
So there are really two different parameter counts to think about:
- total parameters stored in the model
- parameters actually used for one token step
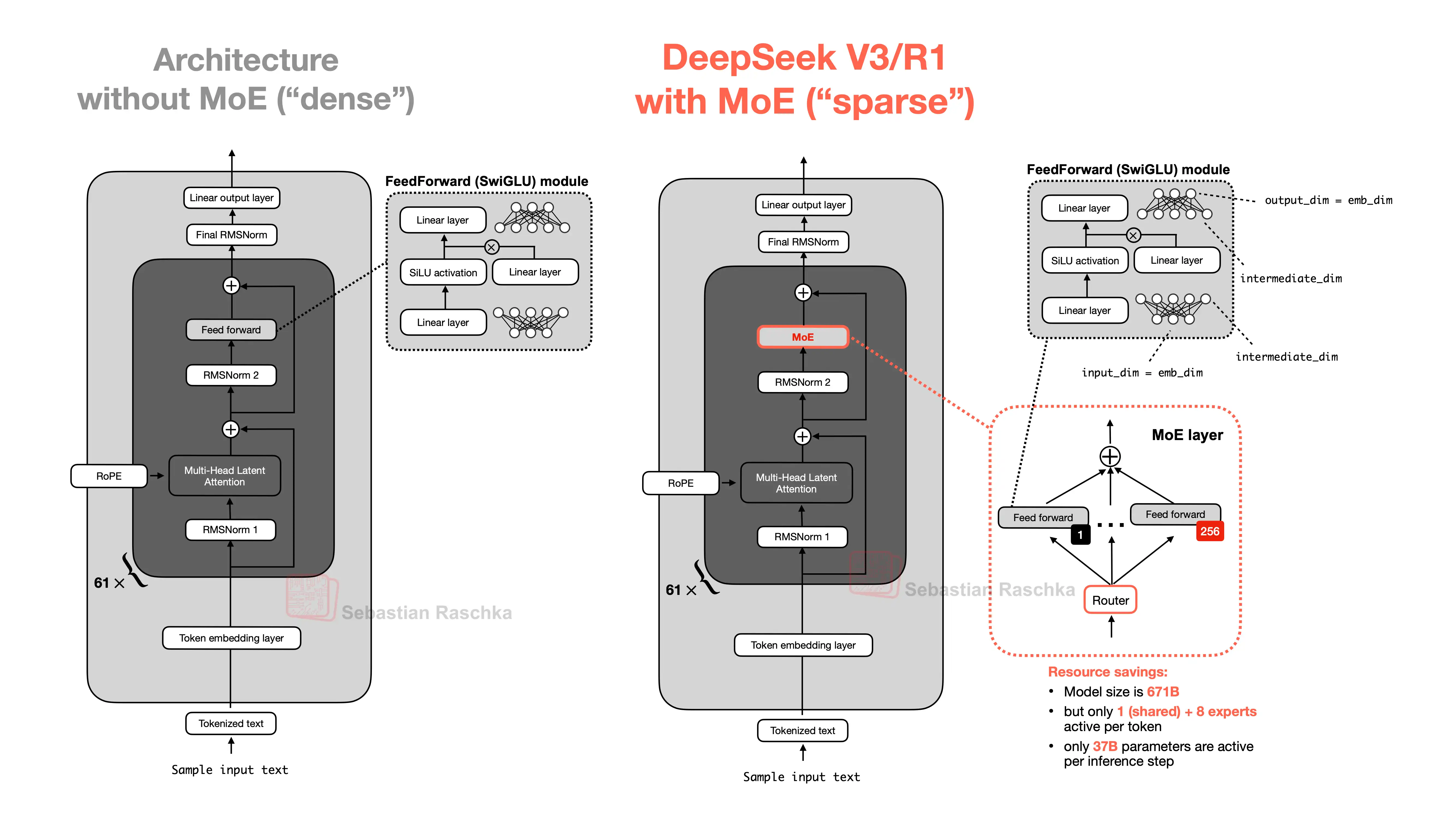
This is what gives MoE its appeal. The model can have a large total capacity, but it does not have to pay the full dense-compute price on every token.
The repo’s MoE materials make this concrete: with many experts and a small top_k, only a fraction of the total expert parameters are active per token.
That is why people often say MoE gives you:
- large total capacity
- lower active compute than an equally large dense model
But that does not mean MoE is free. You still pay for:
- storing the experts
- routing overhead
- added implementation complexity
- potential load-balancing issues
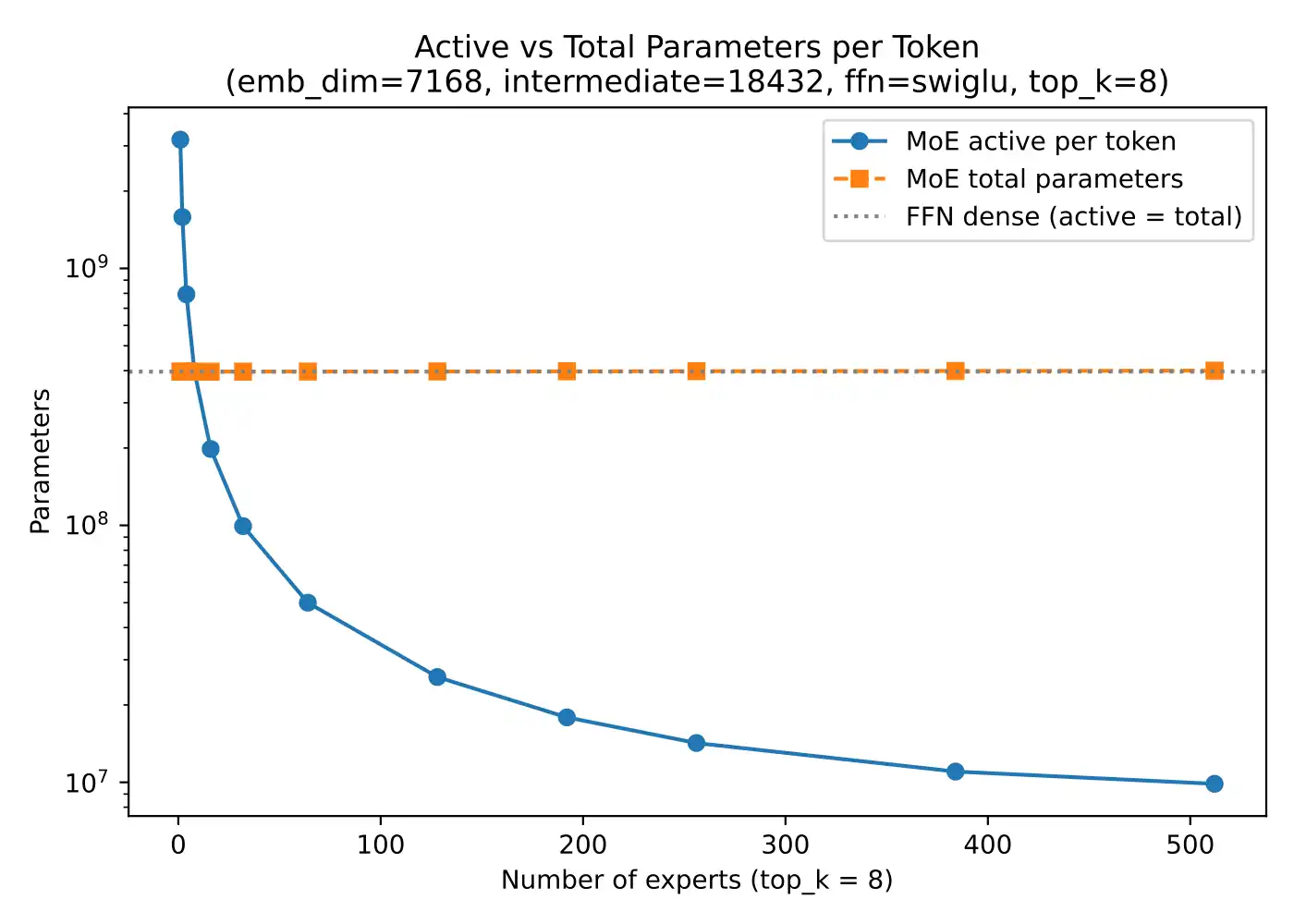
So MoE should be thought of as sparse activation, not “same as a small model.” It is a way to keep large representational capacity while activating only part of it for any given token.
In short, MoE models have huge parameter counts because many experts are stored in the model, but active compute per token is lower because only a small routed subset of those experts is used on each forward pass.