Machine Learning FAQ
What are the main reasons an LLM project fails on consumer hardware?
LLM projects often fail on consumer hardware because the real memory and systems cost is much larger than people expect from the model size alone.
The most common failure modes are:
- choosing a model that is simply too large
- using too long a context length
- using too large a batch size
- trying full finetuning when LoRA would be more realistic
- hitting large memory spikes during checkpoint loading
- ignoring practical optimizations such as
bfloat16or KV-cache-aware design

Another reason projects fail is that people think only about weights, but real workloads also need space for:
- activations
- gradients
- optimizer state
- KV cache during generation
On consumer hardware, those extra costs often dominate.
The repo’s performance notes also show that a handful of practical optimizations can make a big difference before you ever need multi-GPU infrastructure.
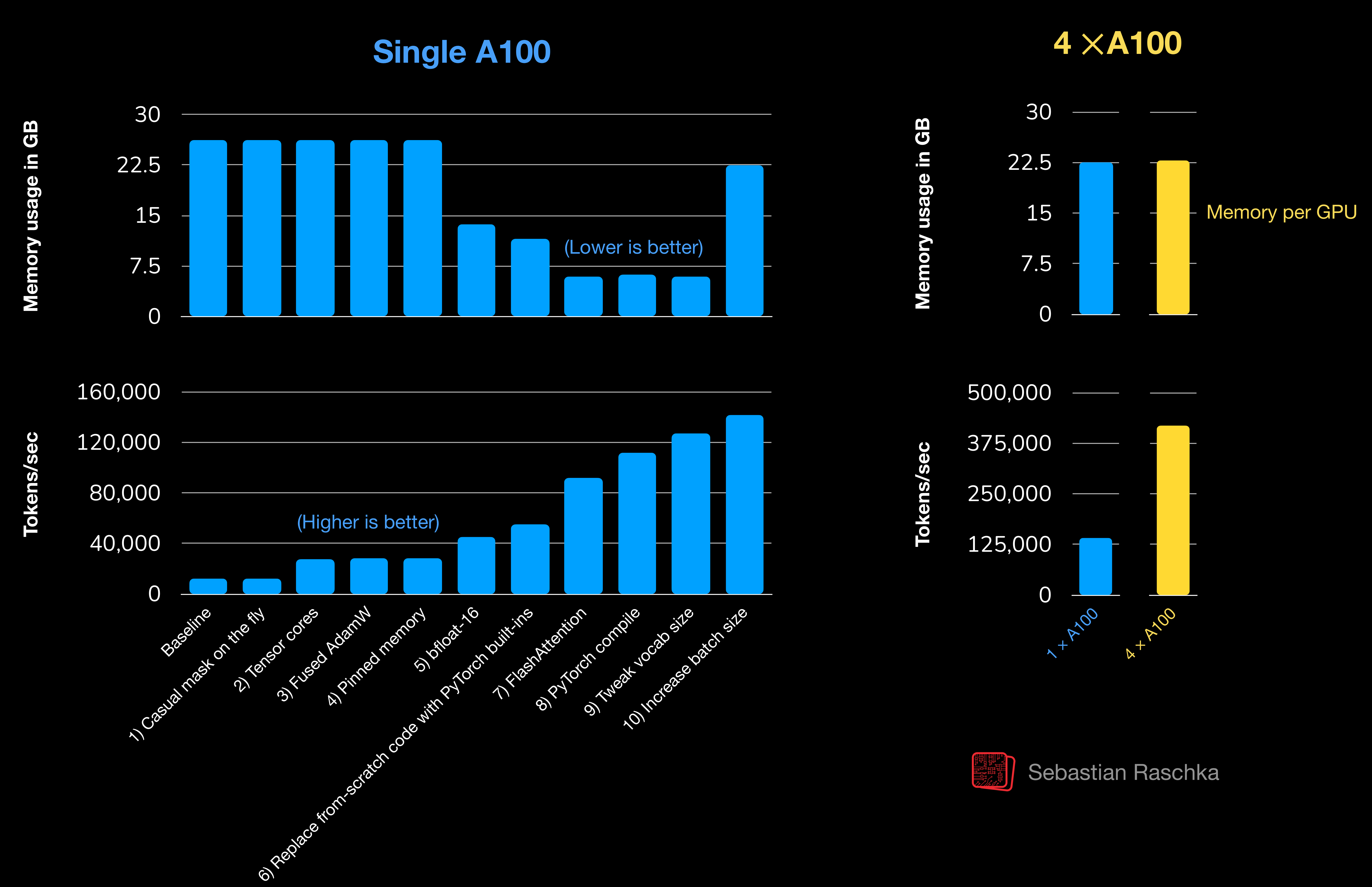
So the common pattern is:
- unrealistic model and context choices
- underestimating peak memory
- skipping the simplest performance engineering steps
In short, LLM projects fail on consumer hardware mainly because weights are only part of the total memory story, and because long contexts, naive loading, full finetuning, and missing low-level optimizations quickly push small machines past their limits.