Machine Learning FAQ
When should prompt tokens be masked out of the loss during instruction finetuning?
Masking prompt tokens out of the loss is useful when the main goal of instruction finetuning is to improve the assistant response, not to teach the model to reproduce the already-known prompt template.
Without masking, the model is trained to predict everything in the sequence, including:
- template boilerplate
- user prompt tokens
- response tokens
That is valid, but it means some training capacity is spent on learning parts of the sequence that are not the main target of interest.

Masking prompt tokens is especially appealing when:
- the prompt template is fixed and already known
- the main quality concern is response generation
- you want the loss to reflect answer quality more directly
The repo’s chapter 7 materials also show the practical mechanism: use an ignore index so certain positions do not contribute to the loss.
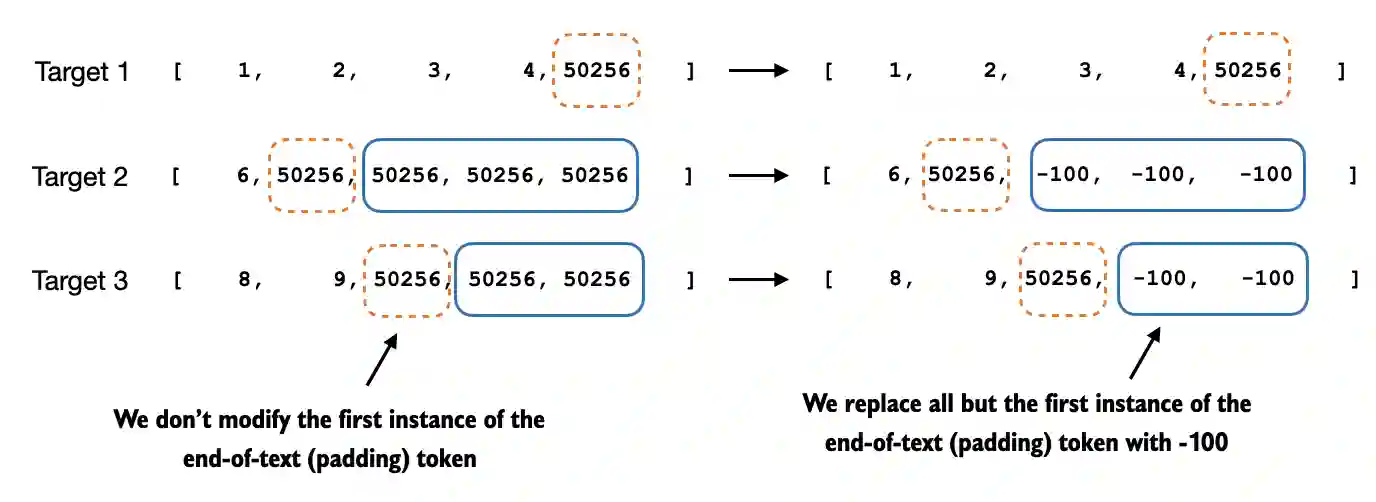
This is not a strict rule, though. Leaving prompt tokens in the loss can still be reasonable if you want the model to internalize a specific format very strongly or if the prompt structure itself varies meaningfully across examples.
So the real question is what you want the model to spend its capacity on.
In short, prompt tokens should often be masked out of the loss when the prompt format is fixed and the real training objective is to improve the assistant response, because this keeps the loss focused on the part of the sequence users actually care about.