Machine Learning FAQ
When is GQA enough, and when do you also want sliding-window attention?
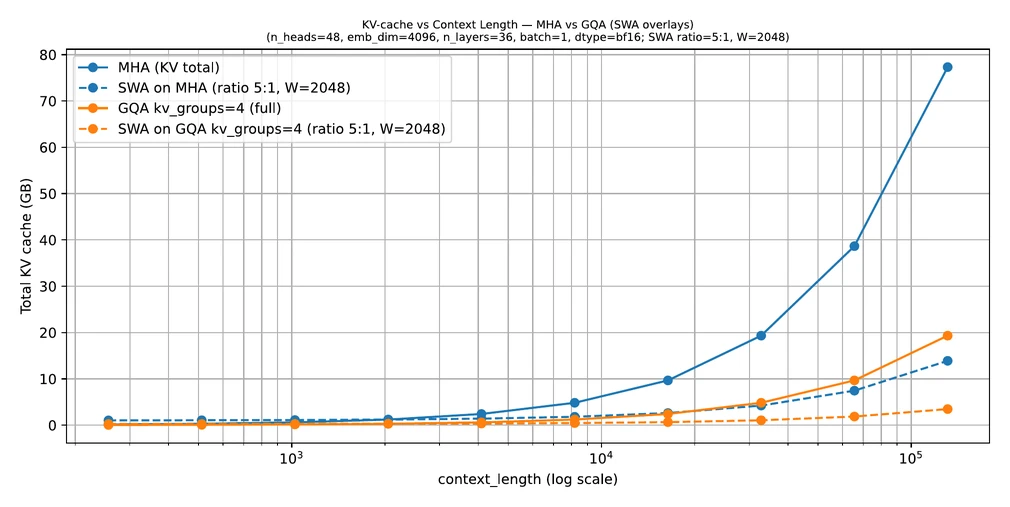
GQA is often enough when your main problem is that full global attention is still useful but the KV cache is too expensive. Sliding-window attention (SWA) becomes attractive when the context is so long that even a GQA-backed global-attention design is still too costly.
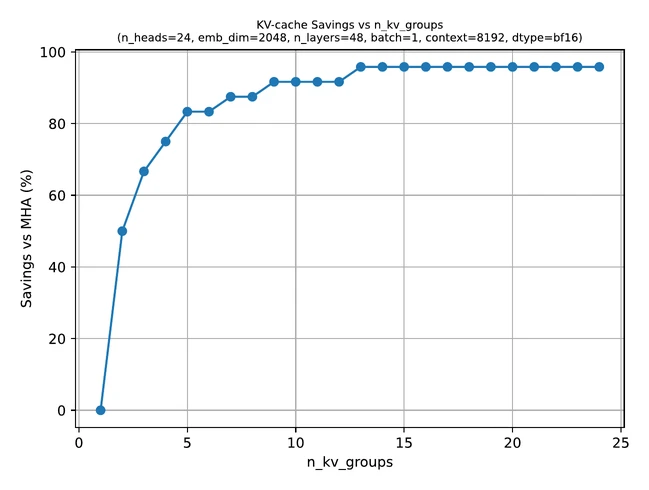
GQA helps by reducing the number of key-value heads while keeping full attention over the available context.
That means it is a good fit when:
- you still want every token to be able to attend broadly
- the main bottleneck is KV-cache memory
- you want a relatively conservative change from standard attention
SWA makes a more aggressive tradeoff. It restricts most tokens to a local window, so it saves more memory and compute at long contexts, but it also gives up the simplicity of full global attention everywhere.
That is useful when:
- context length is very large
- local context matters more than unrestricted global context at every layer
- you are willing to use a hybrid design such as mostly local layers plus occasional global layers
So the practical rule is:
- use GQA alone when full attention still feels worth preserving and you mainly need KV efficiency
- add SWA when long-context costs are still too high and a hybrid local-global pattern is acceptable
That is why models such as Gemma 3 combine the two ideas rather than treating them as competitors.
In short, GQA is enough when you want cheaper full attention, while sliding-window attention becomes worthwhile when very long contexts make even optimized global attention too expensive.