Machine Learning FAQ
What does it mean to align an LLM?
To align an LLM means to shape its behavior so that what it produces is closer to what humans actually want.
A pretrained language model may already be capable in the narrow sense that it can continue text well. But that does not guarantee it will be:
- helpful
- truthful
- safe
- well calibrated
- good at following instructions
Alignment is the broad effort to push the model’s behavior in that direction.
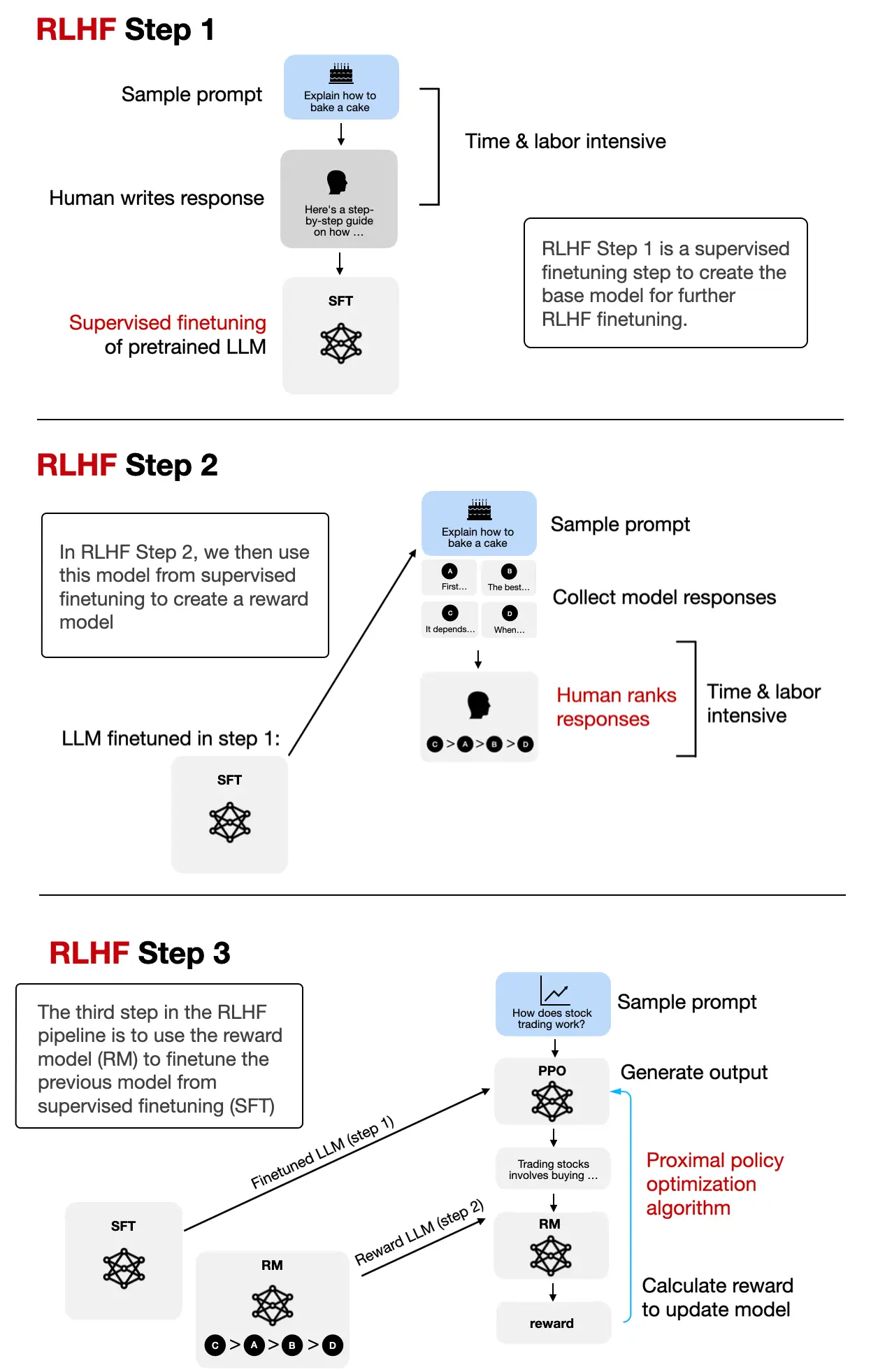
In practice, alignment is usually not one single step. It often includes several stages, such as:
- supervised instruction finetuning
- preference tuning with methods such as DPO
- evaluation for harmful or low-quality behavior
- prompt-template and response-style refinements
This is also why alignment is not the same thing as model size or intelligence. A larger model can still be badly aligned. A smaller model can be quite well aligned for a specific user-facing task.
The goal is not merely “make the model polite.” It is to make the model’s behavior better match the intended use case and the user’s preferences or constraints.
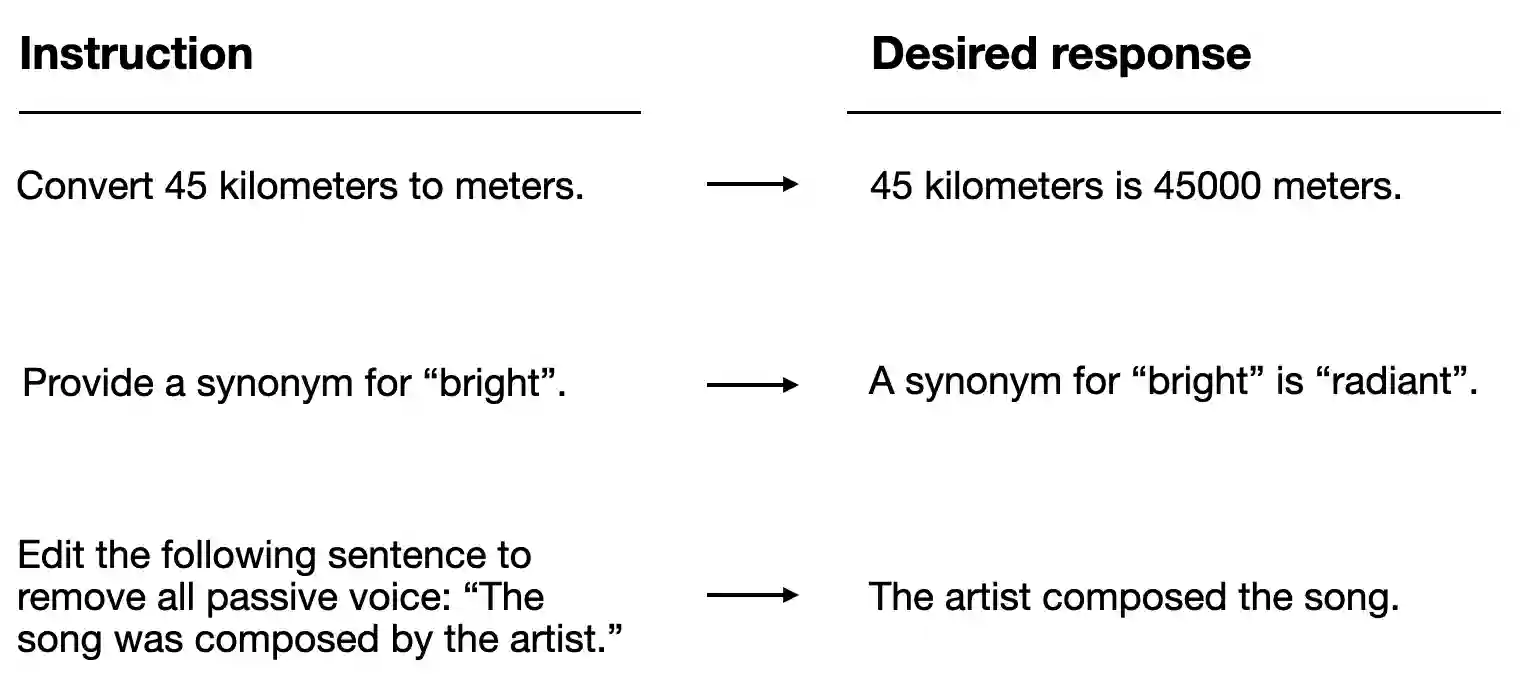
So alignment is best understood as behavioral shaping after raw capability learning.
In short, aligning an LLM means making its outputs better match human goals and preferences, especially around helpfulness, safety, truthfulness, and instruction-following, rather than leaving the model at the level of raw pretrained continuation behavior.