Machine Learning FAQ
How does tokenization work, and why do LLMs usually rely on subword tokenizers such as BPE?
Tokenization is the step that converts raw text into the discrete pieces an LLM can process. The model does not read characters or words directly as strings. Instead, a tokenizer breaks the text into tokens, maps each token to an integer ID, and these token IDs are then mapped to embedding vectors before they are passed into the model.
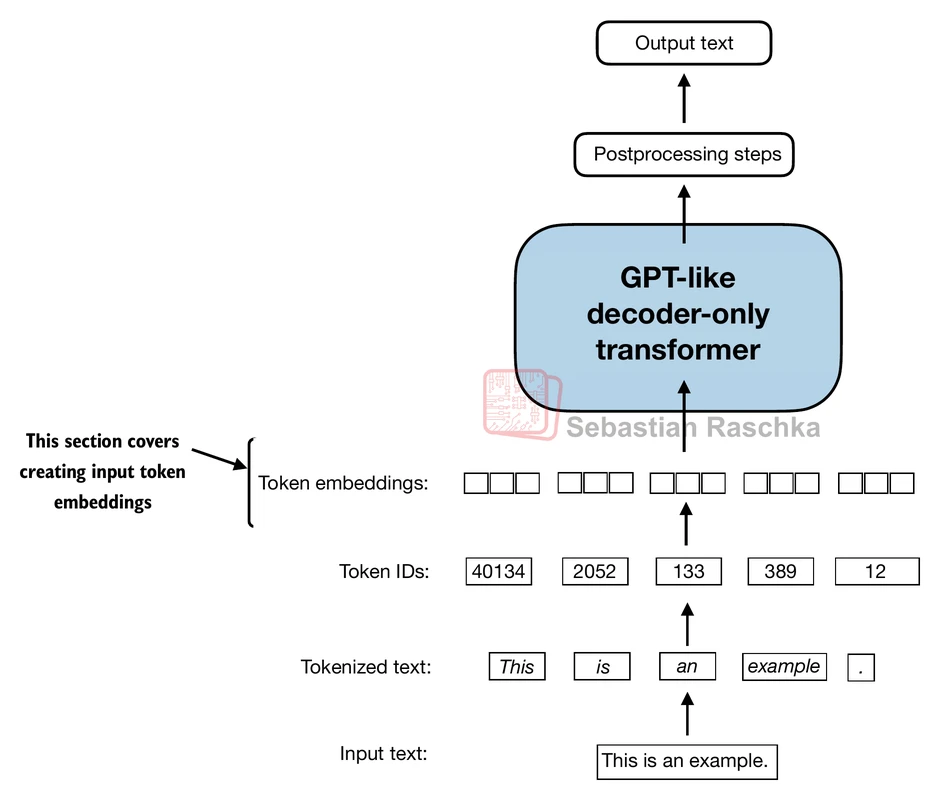
At a high level, tokenization works like this:
- A tokenizer uses a fixed vocabulary of allowed token pieces.
- It splits the input text into tokens according to its rules.
- Each token is mapped to a token ID.
- The model consumes these IDs, not the raw text.
After generation, the reverse process happens: token IDs are decoded back into text.
Why not simply tokenize by whole words? The problem is that a pure word-level vocabulary is brittle. Natural language contains many rare words, new names, misspellings, domain-specific terms, and morphological variants. If a word is not in the vocabulary, a simple word-level tokenizer may have to replace it with a generic unknown token such as [UNK], which throws away information.
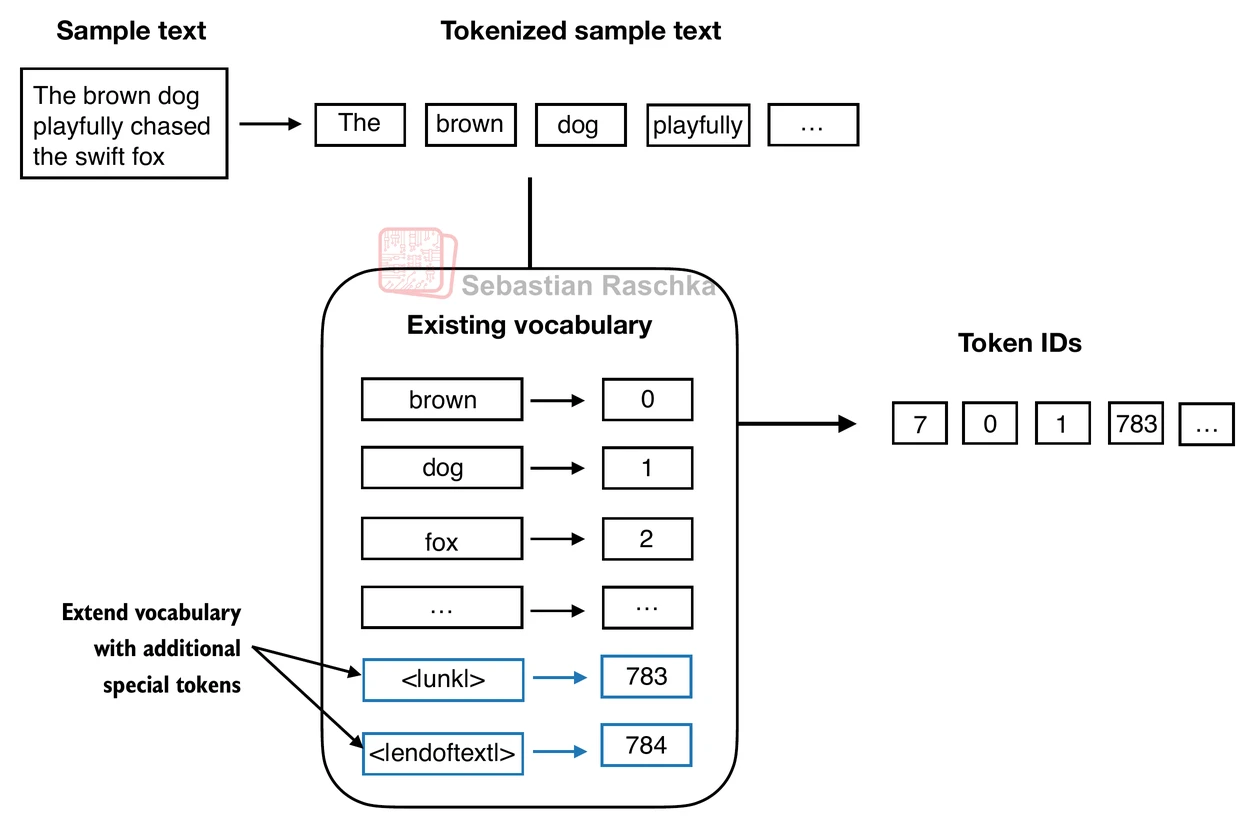
This is why modern LLMs usually rely on subword tokenizers. Instead of insisting that every token be a complete word, they allow a word to be represented as several smaller pieces. So even if the full word is unfamiliar, the tokenizer can still decompose it into known parts rather than collapsing it into a single unknown symbol.
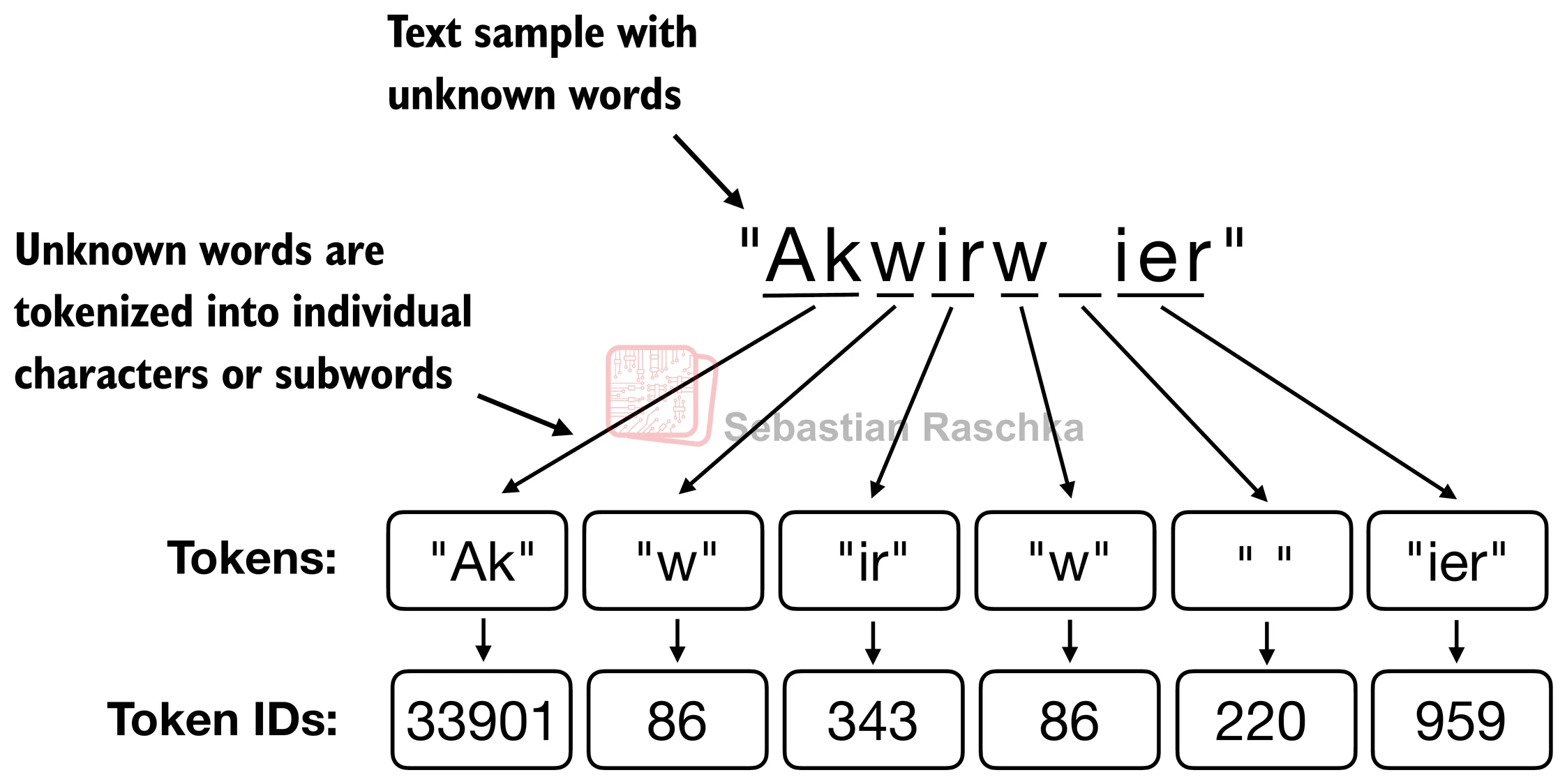
Byte Pair Encoding (BPE) is one of the most common subword tokenization methods. The basic idea is simple: start with small units and repeatedly merge adjacent pairs that occur frequently in the training corpus. Over time, this builds a vocabulary containing common subwords and, for very frequent cases, even whole words. In practice, this means the tokenizer can represent text using a mix of short and long pieces depending on what is common in the data.
This design is attractive because it strikes a practical balance:
- It avoids many out-of-vocabulary problems that arise with pure word-level tokenization.
- It usually produces shorter sequences than character-level tokenization, which is computationally helpful.
- It can reuse recurring fragments such as prefixes, suffixes, and roots across many different words.
- It lets common words stay compact while still being able to represent rare or newly encountered words.
For GPT-style models, BPE is often implemented in a byte-level form, which means that any input text can in principle be represented without needing a dedicated unknown token. That is one reason GPT-2-style tokenizers are more flexible than simple word lookup tables.
In short, tokenization turns text into token IDs so an LLM can process it, and subword tokenizers such as BPE are widely used because they preserve coverage for rare words while keeping the vocabulary and sequence lengths manageable.