Machine Learning FAQ
How do temperature, top-k, and top-p sampling differ?
After an LLM produces logits for the next token, you still have to decide how to turn those scores into an actual token choice. That is what decoding settings such as temperature, top-k, and top-p control.
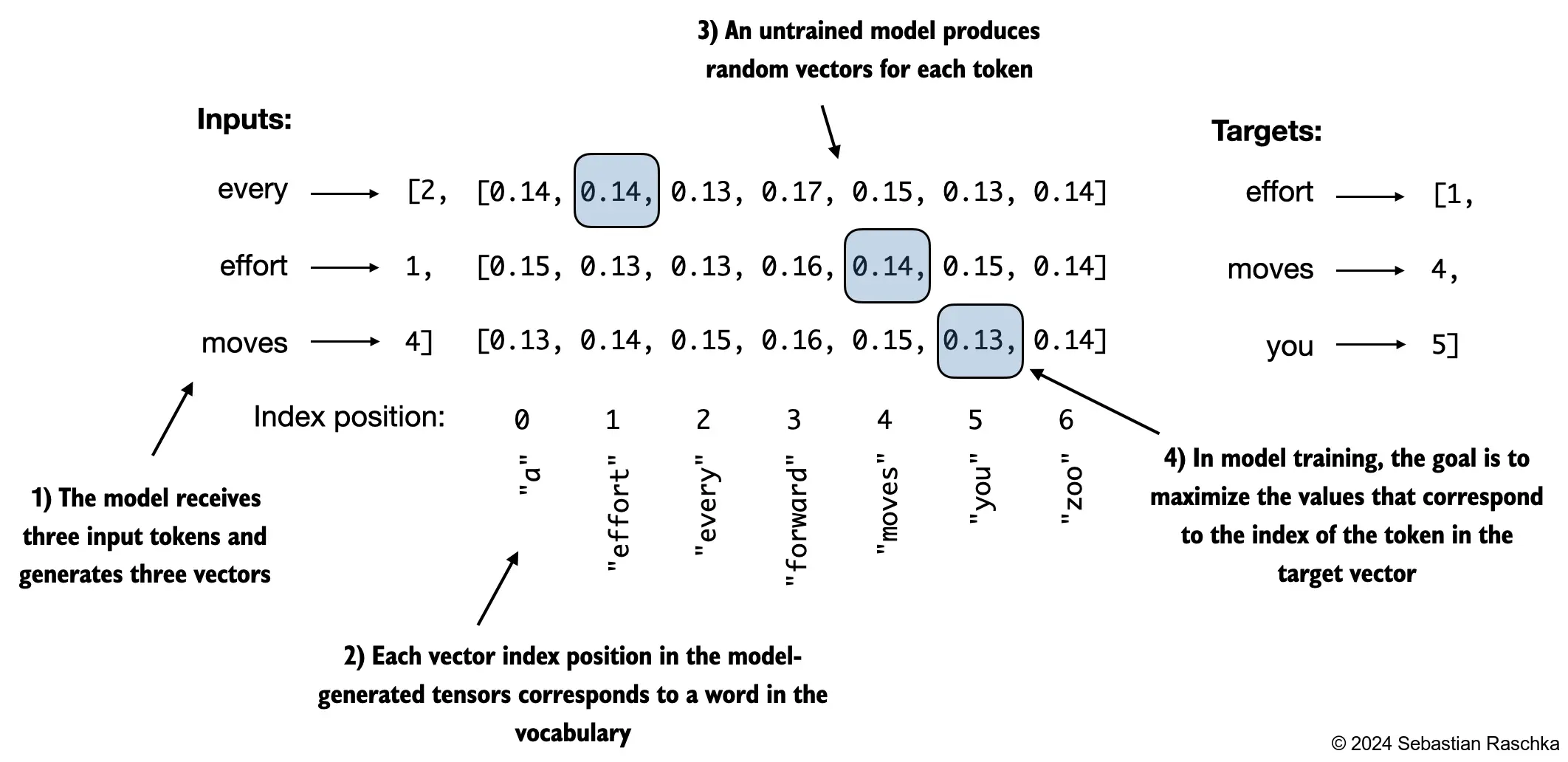
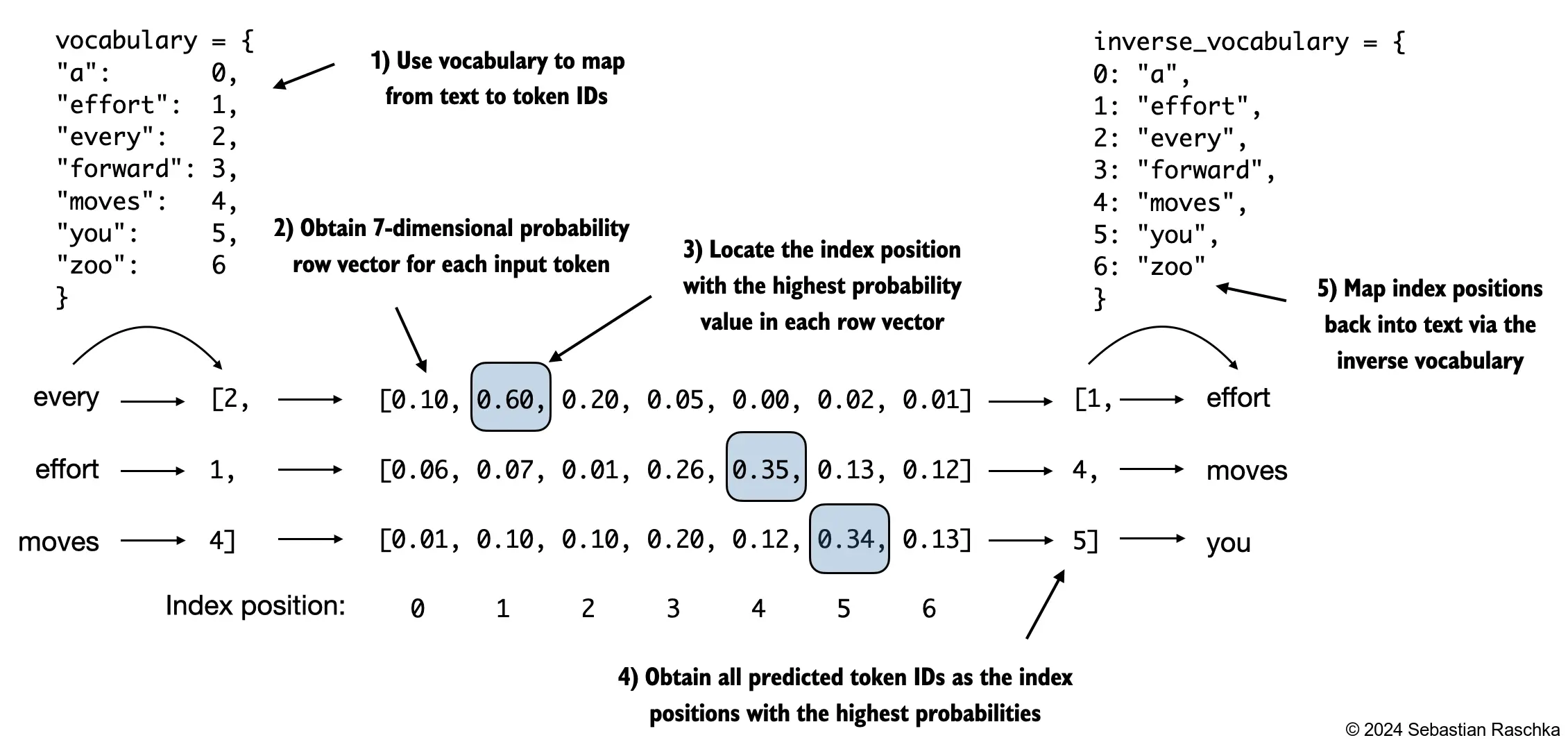
The repo’s generation chapter shows the basic setup: the model produces a distribution over the vocabulary, and text generation turns that distribution into a token sequence.
Here is the difference between the three controls.
Temperature
Temperature changes how sharp or flat the probability distribution is before sampling.
- lower temperature makes the model more conservative and deterministic
- higher temperature makes the model more random and exploratory
At temperature = 0, generation is effectively greedy if implemented that way.
Top-k
Top-k keeps only the k highest-probability next-token candidates and discards the rest before sampling.

If k = 1, top-k becomes greedy decoding. If k is larger, the model can explore multiple strong candidates while still ignoring the long tail of very unlikely tokens.
Top-p
Top-p, also called nucleus sampling, keeps the smallest set of tokens whose cumulative probability reaches a threshold p, such as 0.9 or 0.95.
That means top-p adapts to the shape of the distribution:
- if one or two tokens dominate, it keeps only a small set
- if the distribution is flatter, it keeps more options
So the difference is:
- temperature changes the shape of the distribution
- top-k imposes a fixed-size candidate pool
- top-p imposes a fixed probability-mass pool
These methods are often combined. For example, you might use a moderate temperature and then apply top-p sampling so the model stays diverse without wandering too far into low-probability nonsense.
In short, temperature controls randomness by sharpening or flattening probabilities, top-k keeps only the k most likely tokens, and top-p keeps only the smallest set of tokens whose cumulative probability reaches a chosen threshold.