Machine Learning FAQ
What is sliding-window attention, and when is it useful?
Sliding-window attention (SWA) is a local-attention mechanism in which each token attends only to a fixed-size recent window instead of attending to the entire available prefix.
If standard causal attention is global over all earlier tokens, sliding-window attention is local over a bounded region.
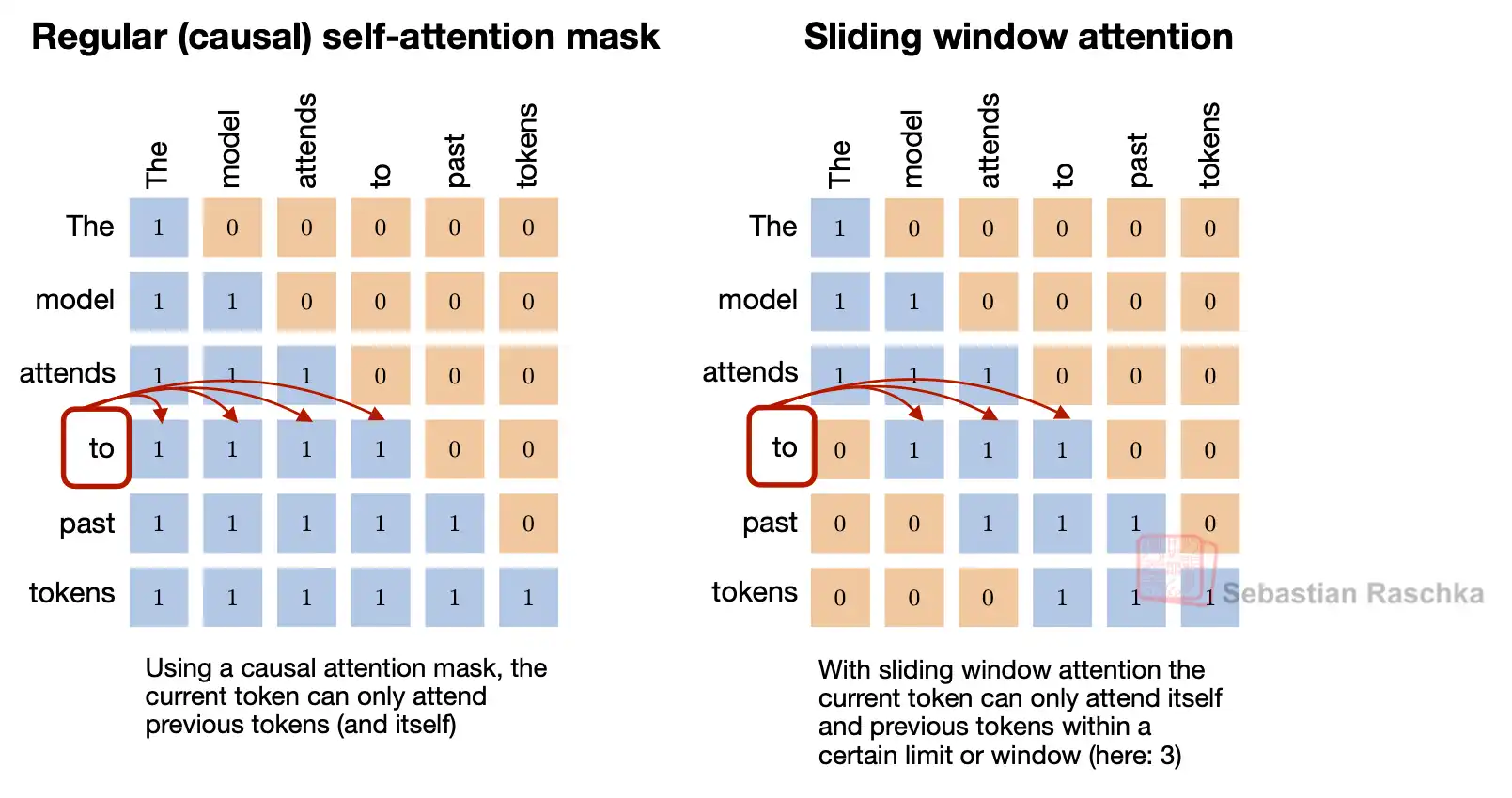
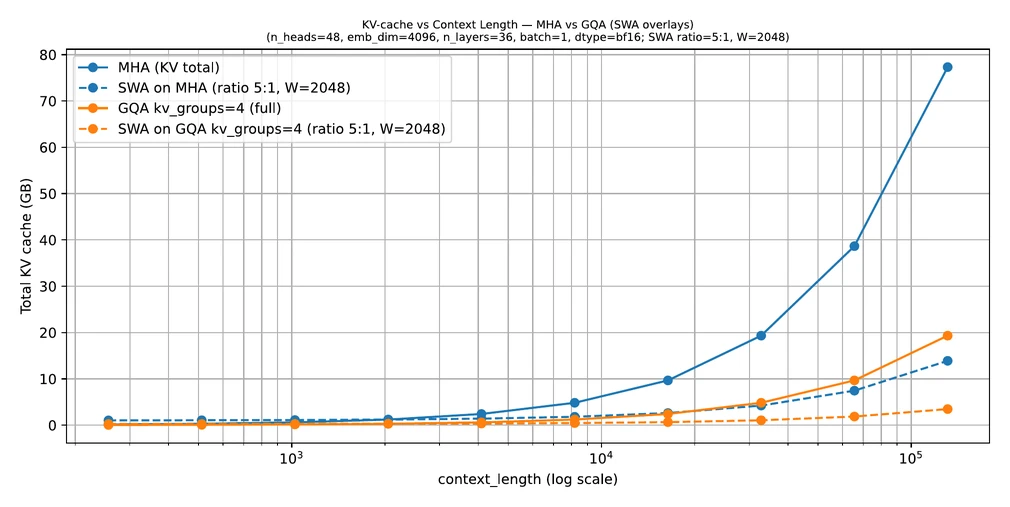
This is useful because the memory cost of long-context attention is heavily tied to the size of the context, especially once a model stores past keys and values in a KV cache. If each token only needs access to a recent window, the cache and effective attention workload can become much smaller.
That is why SWA is attractive for long-context inference. It can reduce memory and compute while keeping enough local context for many tasks.
The repo’s SWA material discusses this in the context of Gemma-family models. The key design idea is that not every layer must have full global attention. A model can mix local attention layers with occasional global layers and still work well in practice.
That hybrid design is important because pure local attention can be too restrictive. Some tasks require information from far back in the sequence. A common compromise is:
- many local sliding-window layers for efficiency
- occasional full-attention layers for longer-range mixing
So when is sliding-window attention useful?
- when the context is long enough that full attention becomes expensive
- when inference memory is a bottleneck
- when nearby context is often much more important than distant context
- when the architecture can compensate with occasional global layers or other long-range mechanisms
It is especially appealing in models that already combine other efficiency ideas such as GQA and KV caching. In those cases, SWA becomes one more lever for making long-context inference practical.
The tradeoff is straightforward:
- pro: lower memory and computation
- con: less direct access to far-away tokens
So the question is not whether SWA is universally better than full attention. It is whether the local-window restriction is acceptable for the use case and architecture.
In short, sliding-window attention is a local-attention variant that restricts each token to a recent context window, and it is most useful when long contexts make full attention too expensive and a model can tolerate or compensate for that locality bias.