Machine Learning FAQ
What are the tradeoffs between short-context and long-context LLMs?
The tradeoff between short-context and long-context LLMs is basically a tradeoff between cost and scope.
A short-context model is cheaper to train and serve. A long-context model can consider much more text at once, but it pays for that with higher memory use, more compute, and more engineering complexity.
For short-context models, the advantages are straightforward:
- lower training cost
- lower inference cost
- smaller KV-cache requirements
- simpler deployment on limited hardware
That is often enough for tasks such as short chat turns, lightweight coding help, or prompts that already use retrieval to compress the relevant information.
Long-context models are valuable when the model must directly reason over:
- large documents
- long conversations
- big code files or repositories
- many retrieved passages at once
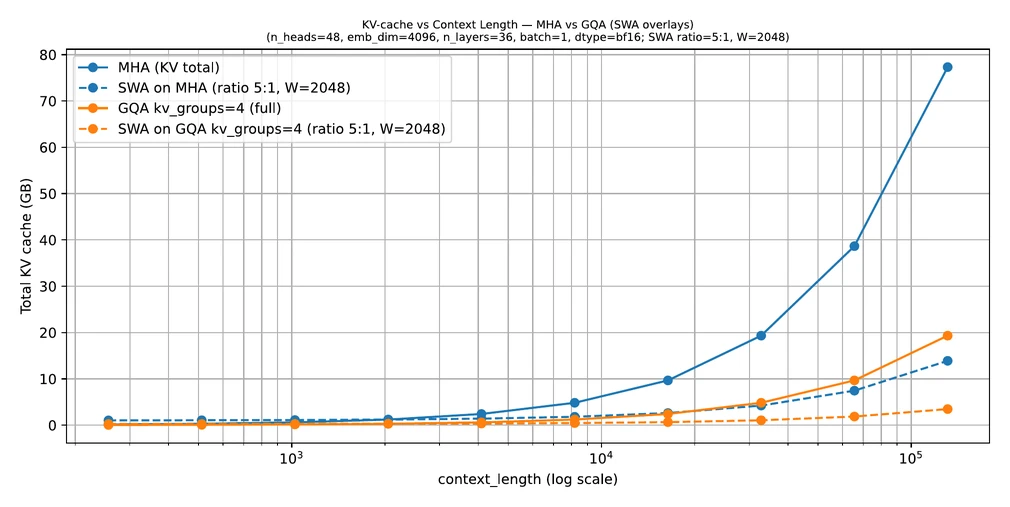
But the cost rises quickly as context gets larger.
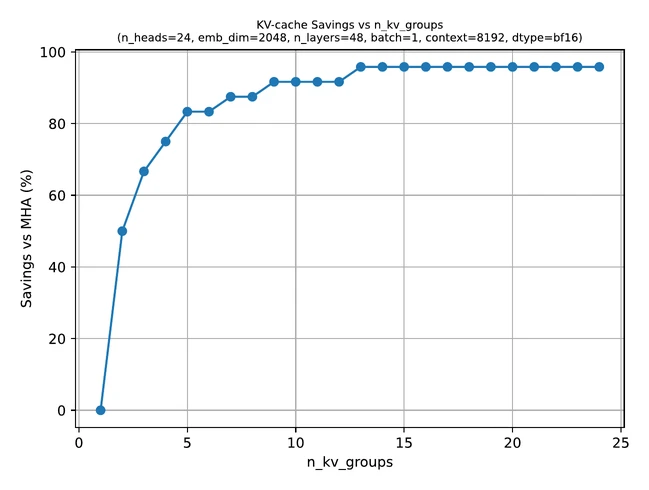
That is why long-context models often need additional design choices such as:
- RoPE-based positional handling
- GQA to reduce KV-cache cost
- sliding-window attention or hybrid attention patterns
- more careful inference engineering
There is also a subtle point: a long context window does not automatically mean the model uses all of it well. A model may technically accept a very long prompt but still degrade in retrieval quality or attention quality across that window.
So the real tradeoff is:
- short context: cheaper and often enough
- long context: more capable for document-scale work, but harder and costlier to do well
In short, short-context LLMs are easier and cheaper to train and serve, while long-context LLMs can operate over much larger inputs but require more memory, more compute, and stronger architectural optimizations to stay practical.