Machine Learning FAQ
What is RoPE, and why did many models move away from learned absolute positional embeddings?
RoPE, short for rotary positional embeddings, is a way of encoding token position directly inside the attention mechanism. Many modern LLMs moved to it because it handles positional relationships more naturally than the older GPT-style approach based on learned absolute positional embeddings.
In the earlier GPT-style setup used in the introductory repo chapters, position is handled by learning a separate positional embedding vector for position 0, position 1, position 2, and so on. These position vectors are then added to the token embeddings at the model input.
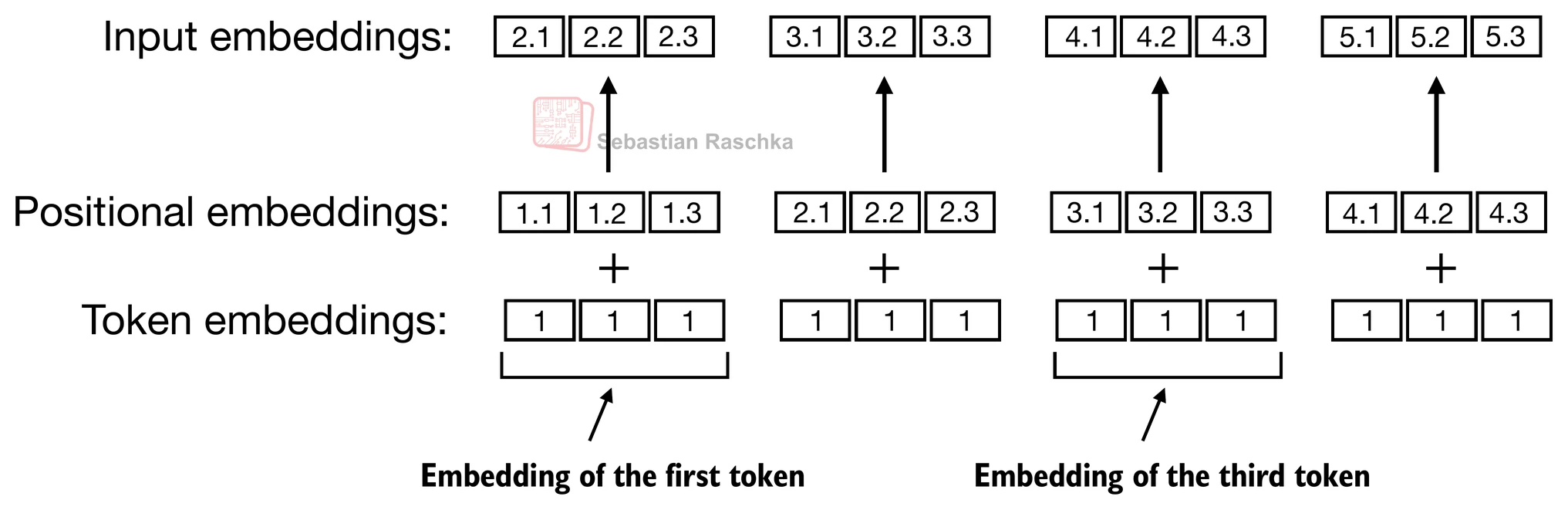
That works, but it has some limitations:
- it ties the model to a fixed learned position table
- it mainly encodes positions as absolute slots
- extending context length beyond the training setup is awkward
RoPE takes a different approach. Instead of adding a learned position vector at the input, it rotates the query and key vectors in attention by position-dependent angles. This makes attention scores depend on relative position in a structured way.
That is the key reason RoPE became attractive: language understanding often depends more on how far apart tokens are than on their raw absolute positions.
The repo’s GPT-to-Llama material shows this architectural shift clearly. Modern Llama-style models keep the same overall decoder-only transformer idea, but they replace learned absolute position embeddings with RoPE.
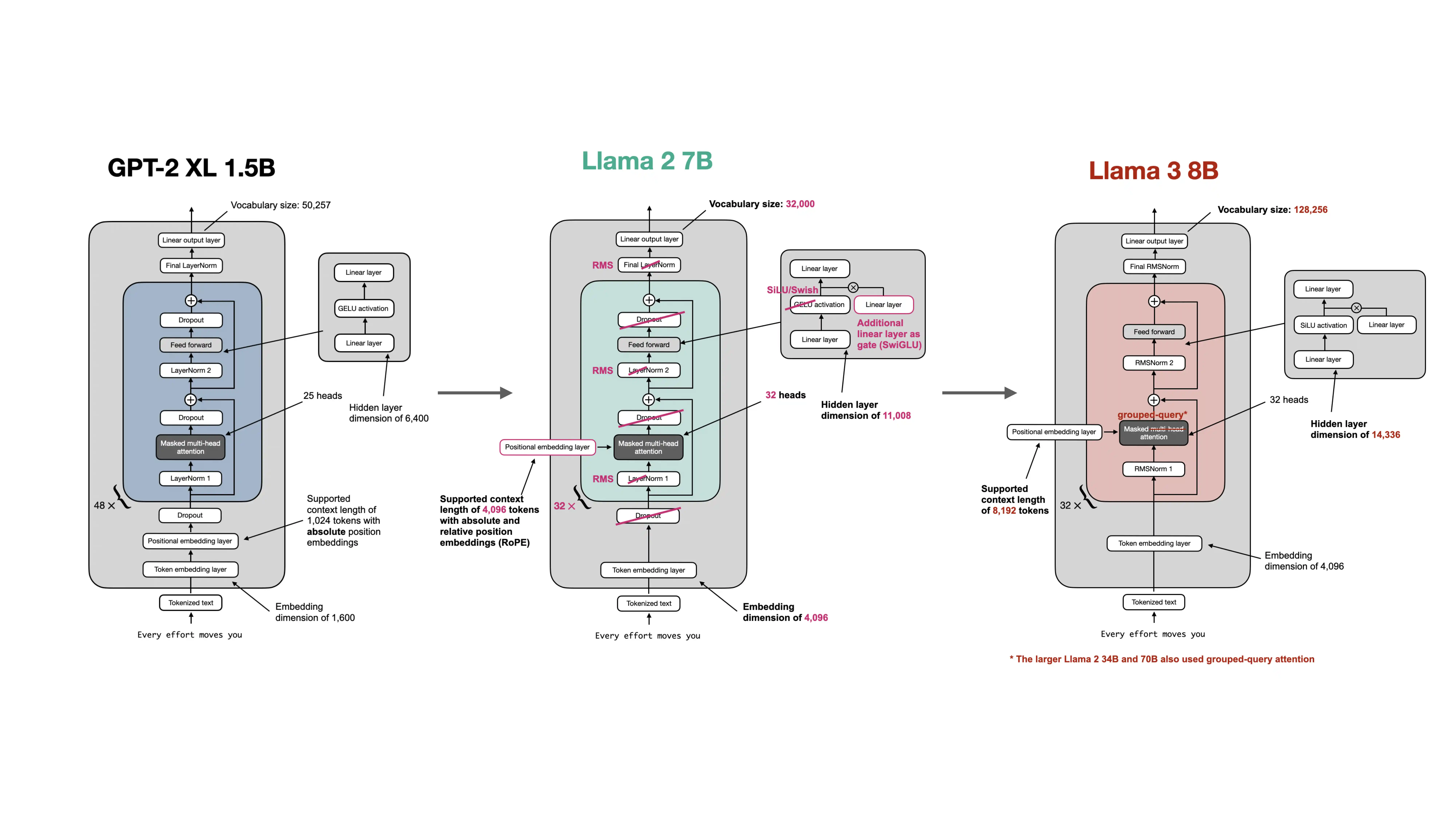
Why did many models move away from learned absolute positional embeddings?
- Better handling of relative distances. RoPE makes the attention interaction itself position-aware.
- Better long-context behavior. It is often easier to extend or adapt RoPE-based models to larger context windows.
- Cleaner integration with attention. Position is encoded where it matters most: in the query-key interaction.
This does not mean learned absolute embeddings are unusable. They are simple, intuitive, and work well in smaller educational GPT implementations. But as models became larger and longer-context use cases became more important, RoPE turned out to be a better default for many modern architectures.
In short, RoPE is a rotary positional encoding method that injects positional information directly into attention, and many modern LLMs prefer it over learned absolute positional embeddings because it captures relative position more naturally and scales more gracefully to long-context settings.