Machine Learning FAQ
How is RLHF different from DPO at a high level?
At a high level, RLHF and DPO are both ways to use preference data to make an LLM behave more like humans want. The difference is in how they turn those preferences into training updates.
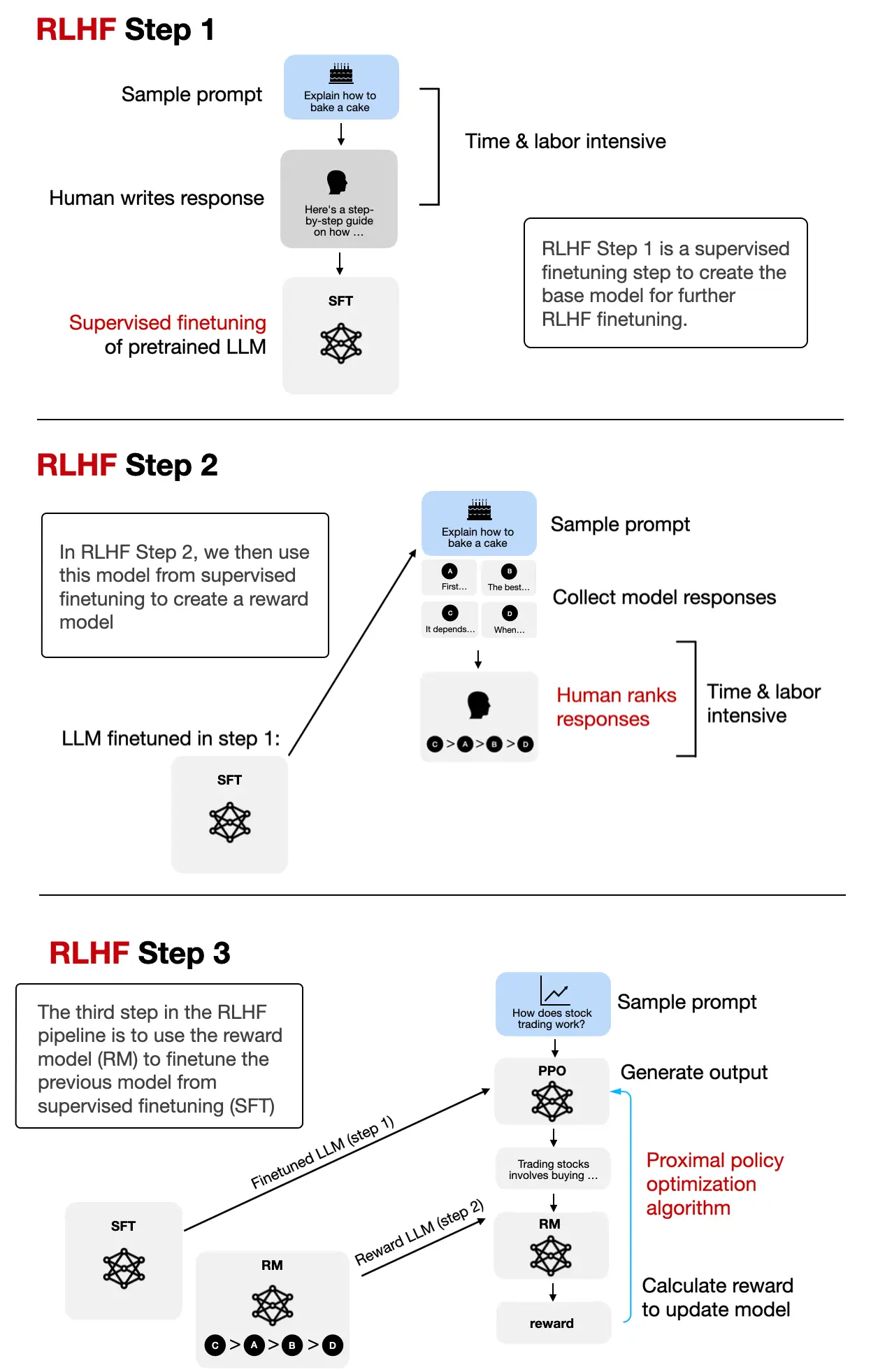
In the classic RLHF pipeline, you usually:
- collect preference data
- train a reward model from that data
- optimize the LLM against that reward model with a reinforcement-learning style procedure
DPO, or Direct Preference Optimization, is simpler. Instead of training a separate reward model and then running a policy-optimization loop, DPO optimizes the language model more directly using chosen-versus-rejected response pairs together with a reference model.
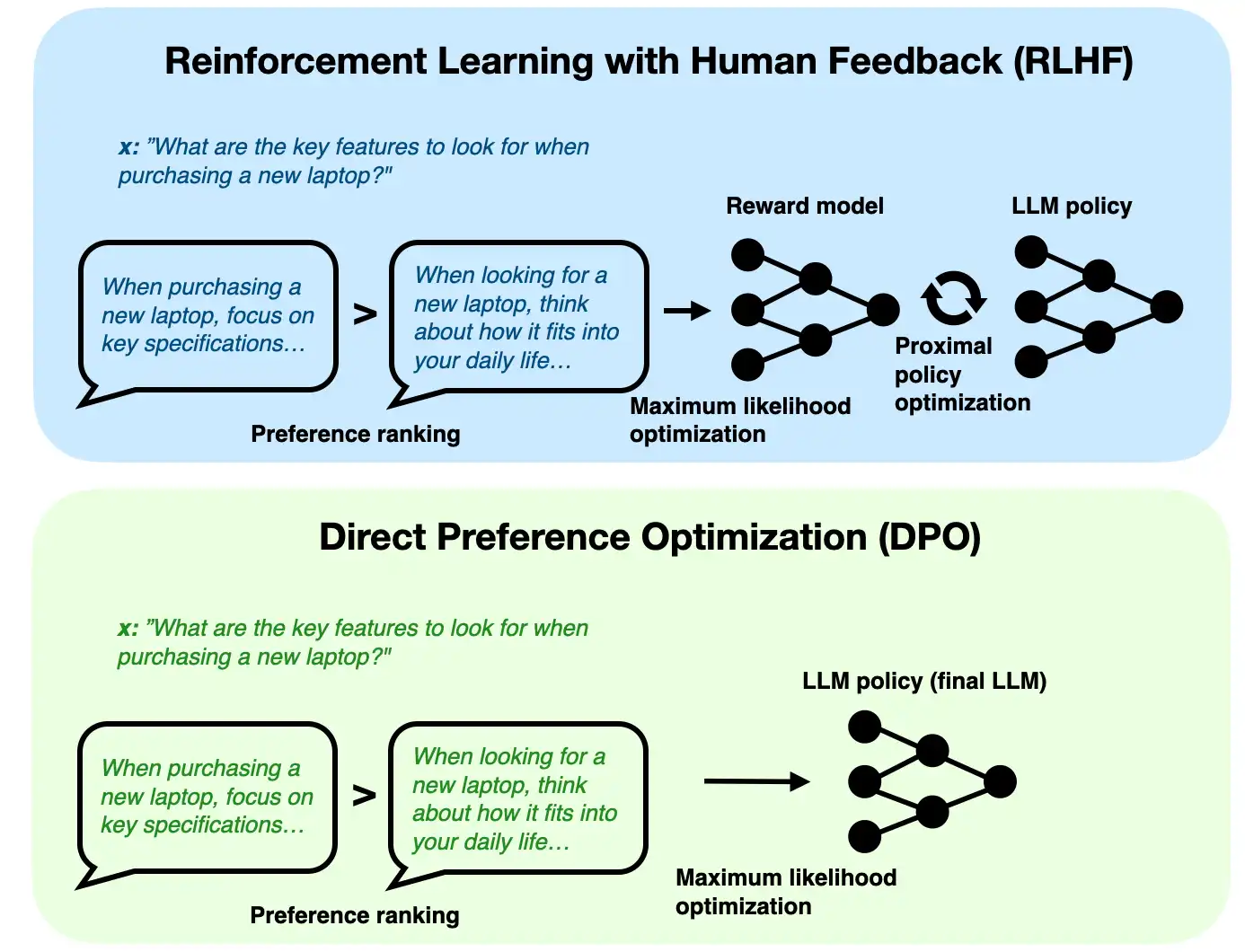
That is the main practical difference:
- RLHF: more components, more complexity, explicit reward-model stage
- DPO: fewer moving parts, more direct optimization from preference pairs
Why did DPO become popular?
- it is simpler to implement
- it is often easier to train stably
- it avoids a separate reward-model training stage
That does not mean RLHF is obsolete. RLHF can still be attractive when you want a richer reward-model setup or a more flexible reinforcement-learning style pipeline. But for many open-model alignment workflows, DPO is easier to use and reason about.
In short, RLHF aligns a model through a reward-model-plus-RL pipeline, while DPO aligns a model more directly from preference comparisons, which is why DPO is often seen as a simpler practical alternative.