Machine Learning FAQ
How do modern open models balance quality, speed, and memory?
Modern open models balance quality, speed, and memory by moving along several design axes at once instead of optimizing only one number such as parameter count.
The most important tradeoff is that stronger models usually want more parameters, more context, and more compute, while faster or cheaper models need architectural shortcuts and smaller active footprints.
Model families such as Qwen, Gemma, and OLMo show this clearly. They are not just “one model.” They are collections of design choices aimed at different points on the quality-speed-memory frontier.
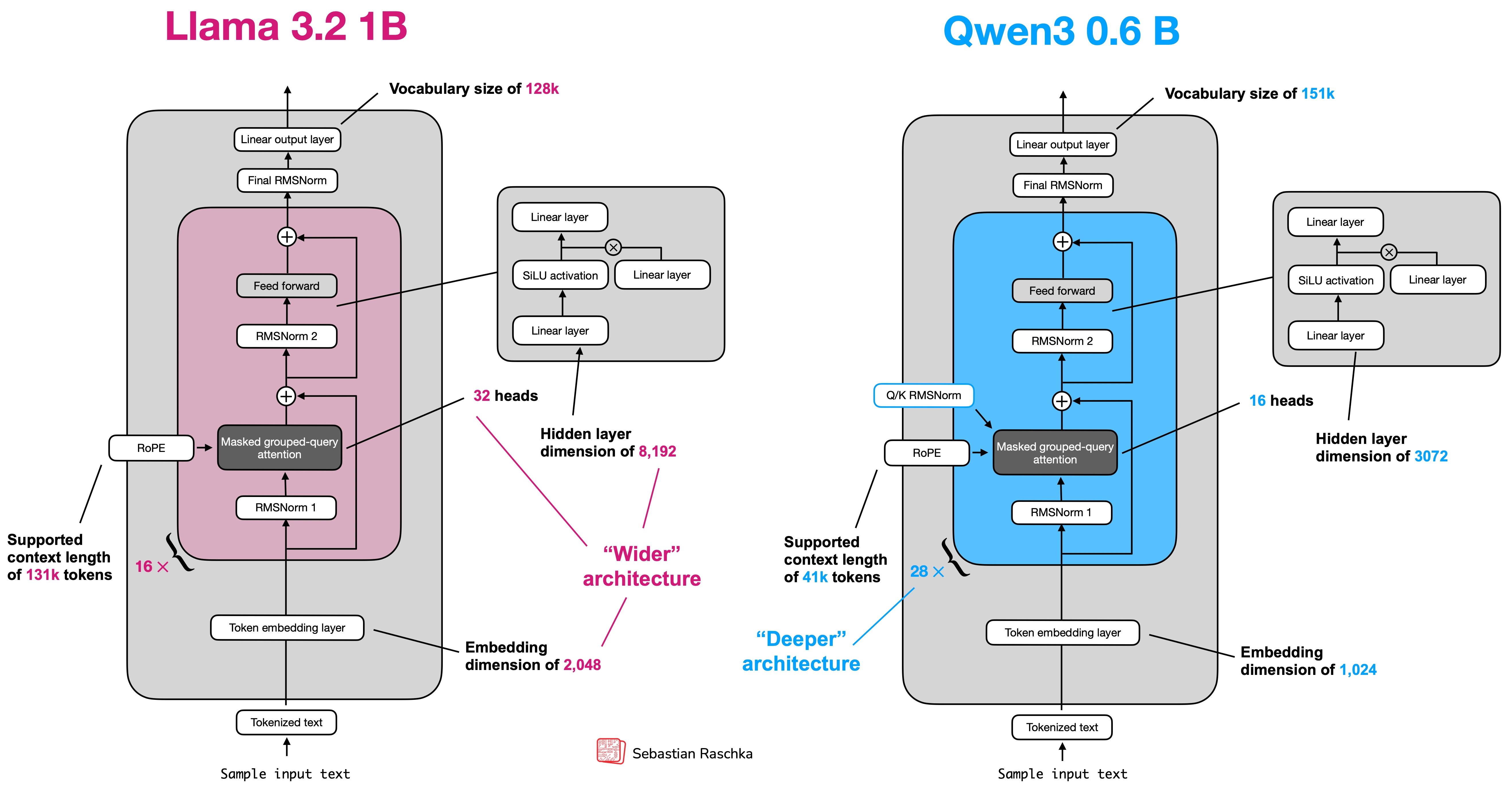
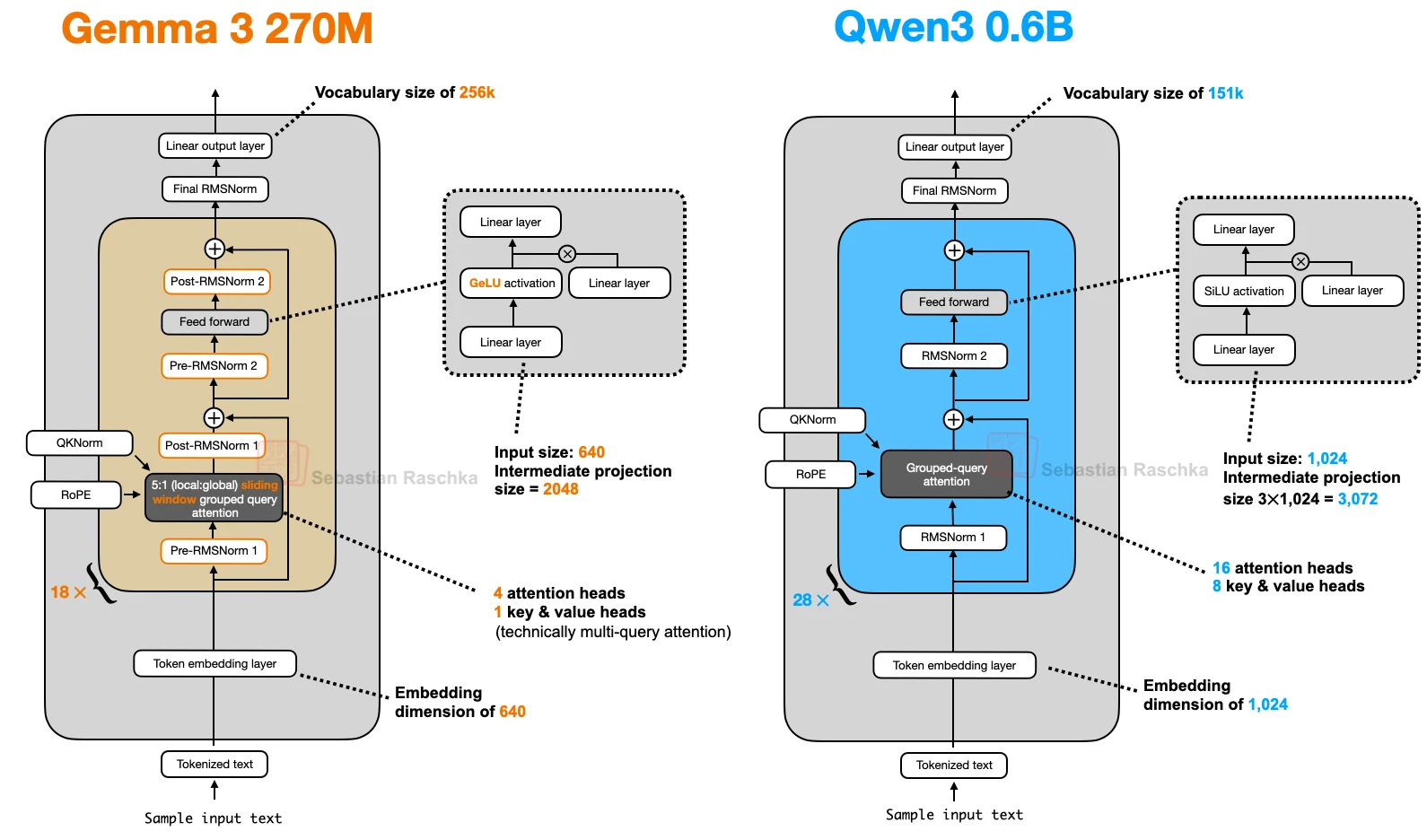
Common architectural levers include:
- RMSNorm for simpler normalization
- RoPE for modern positional handling
- SwiGLU for stronger feed-forward blocks
- GQA to reduce KV-cache cost
- sliding-window attention to make long context cheaper
- MoE to raise total capacity without activating all parameters per token
Those are paired with product-level choices such as:
- smaller versus larger checkpoints
- dense versus sparse MoE variants
- base versus instruct versus reasoning behavior
- shorter versus longer context windows
So modern open models balance quality, speed, and memory by making many incremental decisions, not by discovering one magic architecture.
In short, modern open models balance quality, speed, and memory through a mix of architecture refinements, model-size choices, and product variants, with different families occupying different points on the practical deployment frontier.