Machine Learning FAQ
How does next-token prediction train a large language model?
Next-token prediction trains a large language model by turning ordinary text into a supervised learning problem where the label for each position is simply the token that comes next. This is why LLM pretraining is often called self-supervised: the targets come directly from the text itself rather than from manual annotations.
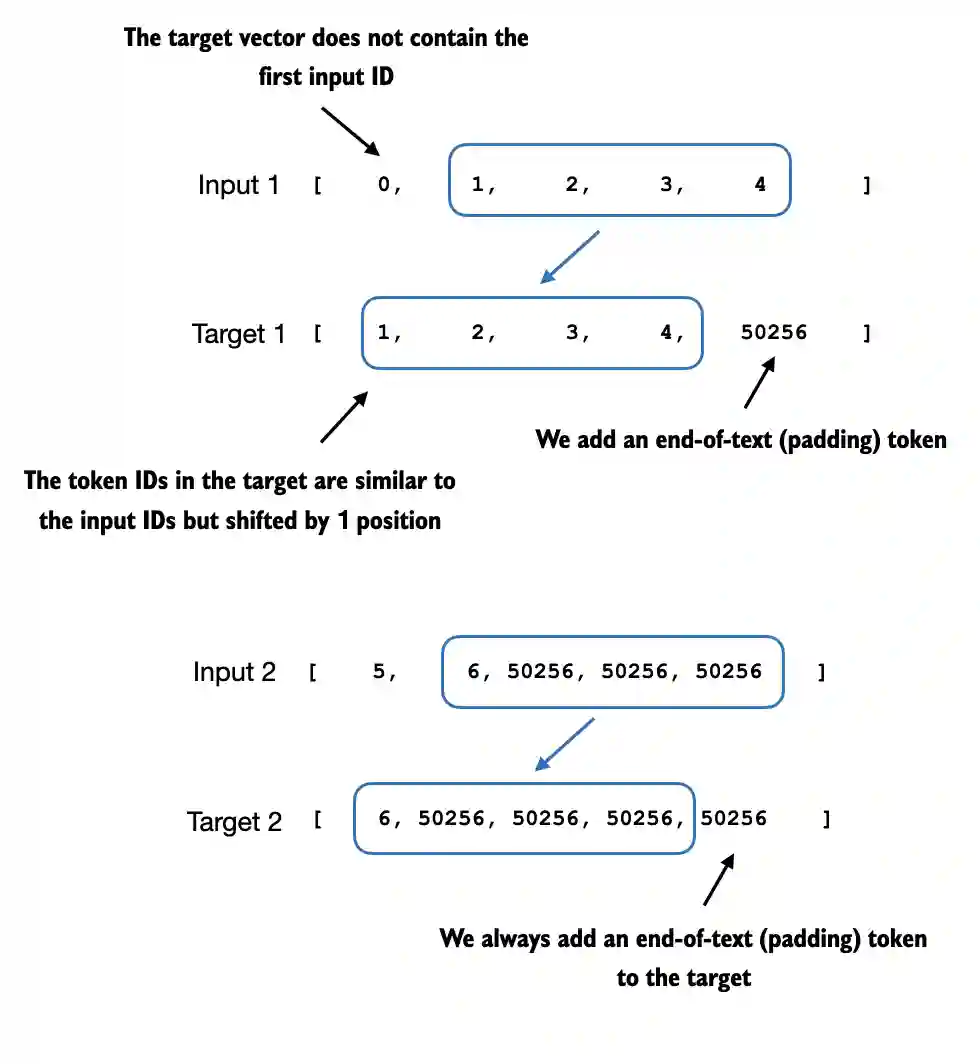
Suppose we tokenize a text sequence into token IDs. During training, the model input is the sequence up to position t, and the target is the token at position t+1. For a whole sequence, the targets are therefore just the inputs shifted by one position:
A GPT-style model then processes the input tokens and produces one logits vector per position. Each logits vector contains one score for every token in the vocabulary and represents the model’s guess about what the next token should be at that position. Because the model uses causal attention, the prediction at each position can only depend on the current token and earlier tokens.
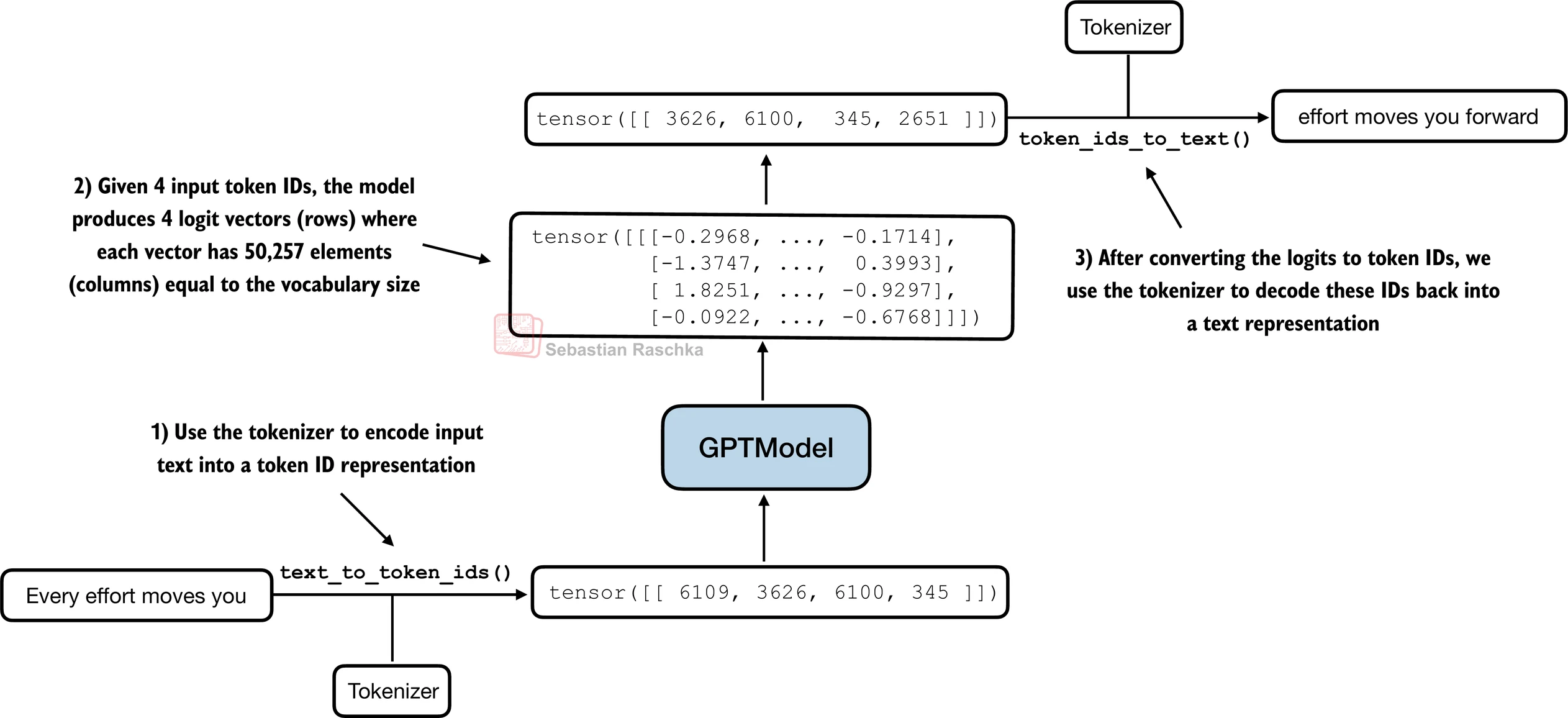
These logits are converted into probabilities, and the model is penalized when it assigns low probability to the actual next token. This penalty is usually computed with cross-entropy loss, which in this context is equivalent to the negative log likelihood of the correct continuation. Backpropagation then updates the model weights so that correct next tokens receive higher probability in similar contexts in the future.

The important point is that the model is not learning a single fixed next-word rule. Over many batches and many documents, it repeatedly learns which continuations are more plausible than others given the preceding context. As a result, it gradually captures syntax, semantics, style, factual associations, and longer-range patterns in language.
It is also useful to distinguish training from generation. During generation, the model predicts one next token, appends it to the context, and repeats. During training, however, it can compute losses for many token positions in parallel within the same sequence, which makes learning much more efficient.
In short, next-token prediction trains an LLM by using shifted text as input-target pairs, scoring the correct continuation at every token position, and updating the model so that real continuations from the training corpus become more probable.