Machine Learning FAQ
What is mixture-of-experts (MoE), and how does it differ from a dense LLM?
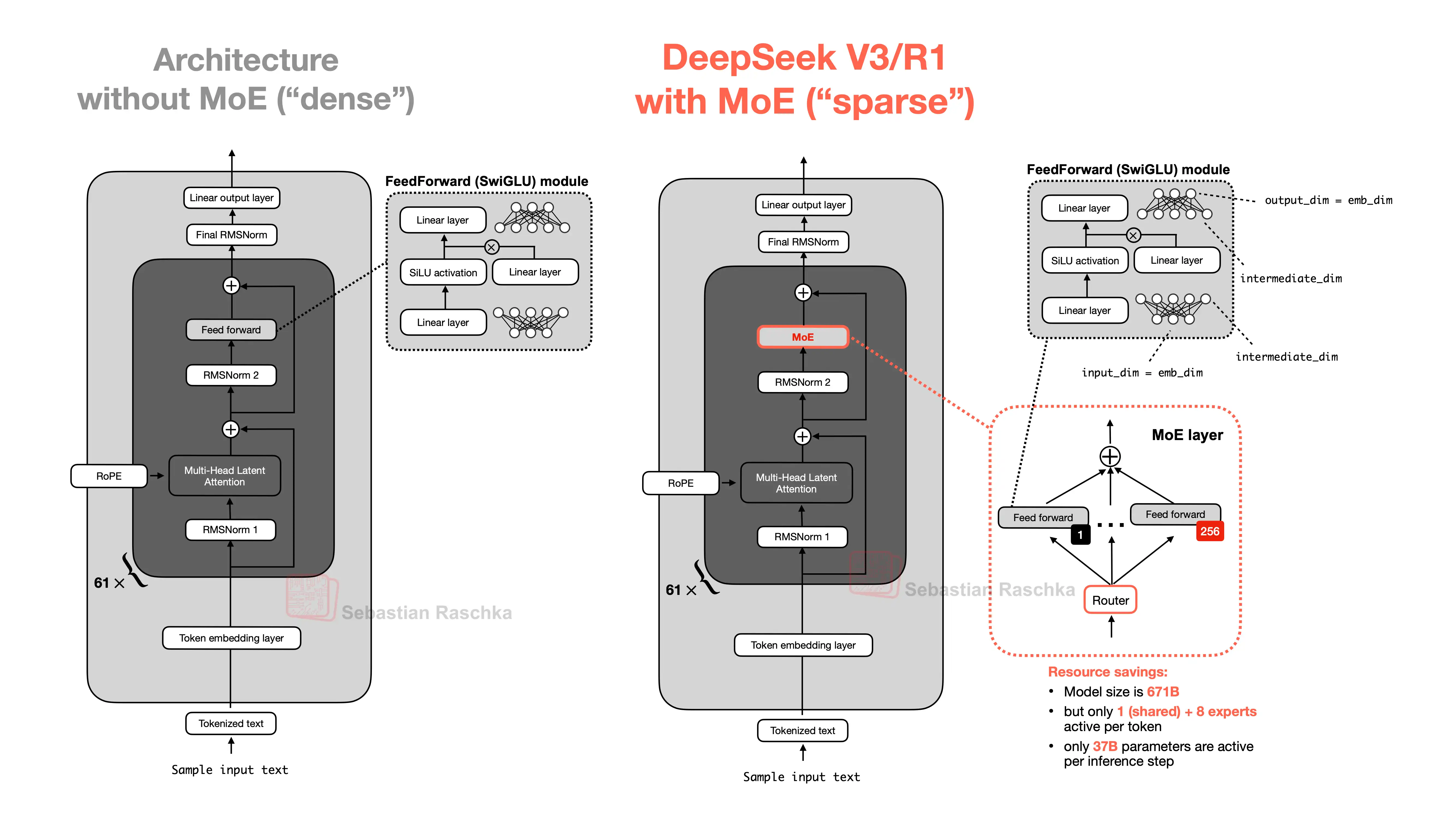
A mixture-of-experts (MoE) model is a sparse LLM architecture in which some layers contain multiple alternative feed-forward networks, called experts, and a router decides which experts each token should use.
This differs from a dense LLM, where every token passes through the same feed-forward network in every transformer block.
The key idea is simple:
- a dense model activates the same parameters for every token
- an MoE model has many more total parameters available, but activates only a small subset for each token
That gives MoE models a useful combination:
- high total capacity, because there are many experts overall
- lower per-token computation, because only a few experts are active at once
This is why MoE models are often called sparse. The full parameter set exists, but any one token only uses part of it.
The repo’s MoE bonus material explains that this is particularly relevant for the feed-forward part of transformer blocks, since feed-forward modules account for a large share of the model’s parameters. Replacing one dense feed-forward module with many experts can massively increase total parameter count without requiring every expert to run for every token.
Some MoE designs also include a shared expert, which is always active, plus a small number of routed experts selected by the router.
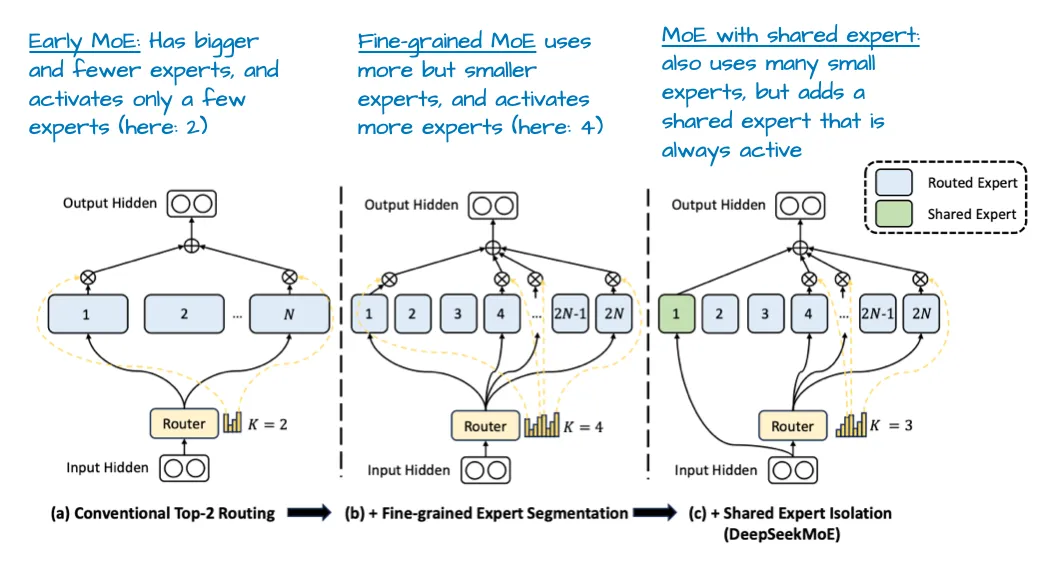
This leads to the main difference from a dense LLM:
Dense LLM
- every token uses the same full feed-forward block
- all relevant parameters are active every time
MoE LLM
- each token is routed to only a few experts
- different tokens can activate different subsets of parameters
The practical advantage is that an MoE can behave like a very large-capacity model without paying the full dense-model cost on every token. That is why MoE architectures are appealing at large scale.
But there are tradeoffs too:
- routing adds architectural complexity
- load balancing can be tricky
- the implementation can be harder to optimize efficiently
- memory and parameter-count stories can be more subtle than the raw headline numbers suggest
The repo’s memory comparison also highlights an important nuance: MoE often reduces active feed-forward memory and compute per token, but total model memory is still influenced by the full parameter set and the rest of the transformer, including the KV cache.
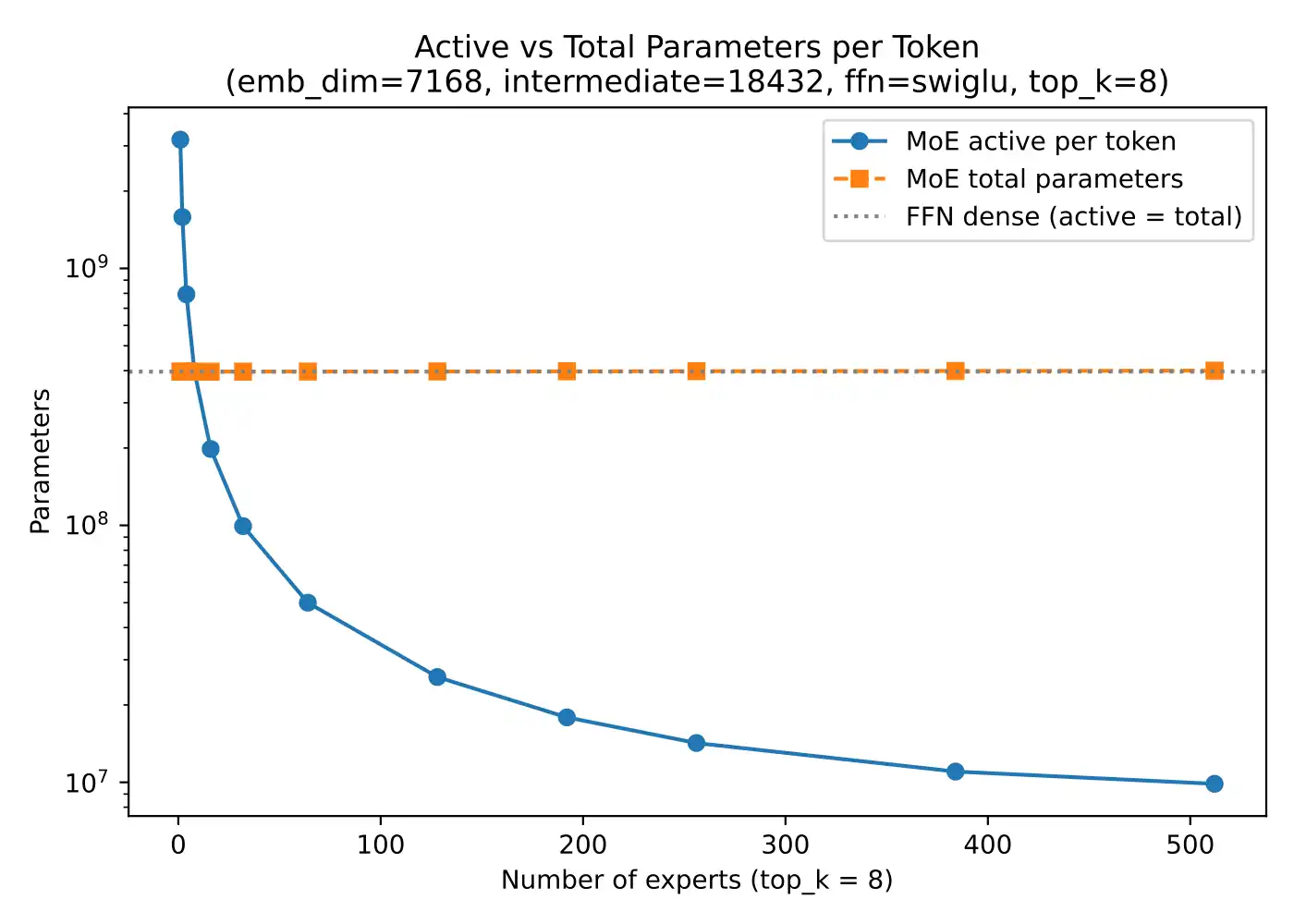
So when people say an MoE model has, for example, hundreds of billions of parameters, the crucial follow-up question is usually: how many of those are active per token?
In short, a mixture-of-experts model differs from a dense LLM by replacing dense feed-forward layers with multiple experts and routing each token through only a few of them, which increases total model capacity without activating all parameters at once.