Machine Learning FAQ
What is LoRA, and when is parameter-efficient finetuning preferable to full finetuning?
LoRA stands for Low-Rank Adaptation. It is a parameter-efficient finetuning method that keeps the original pretrained weights frozen and learns only a small low-rank update for selected linear layers.
Instead of updating a full weight matrix directly, LoRA represents the change with two much smaller matrices whose product approximates the desired update.
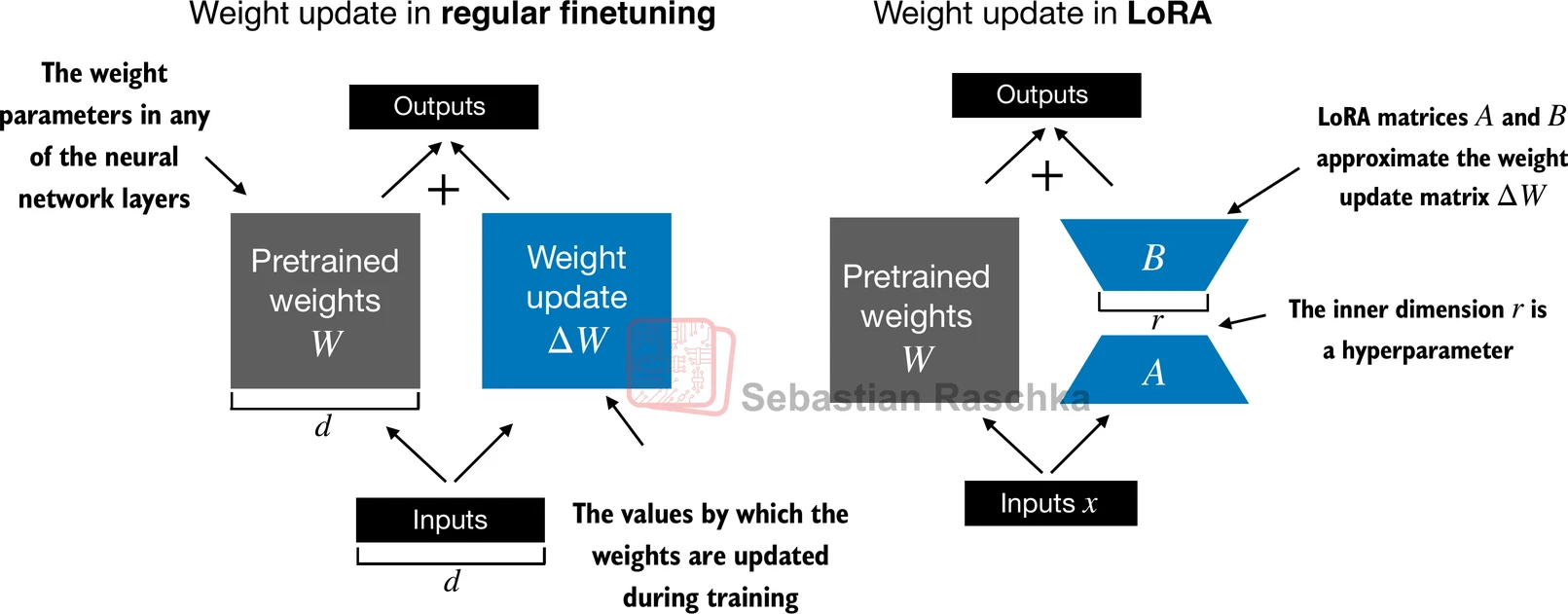
This is attractive because full finetuning of an LLM can be expensive in several ways:
- many parameters must be updated
- optimizer states consume a lot of memory
- storing separate full checkpoints for multiple tasks becomes heavy
- training cost rises quickly with model size
LoRA reduces that burden by adding a small trainable path on top of the frozen base layer.
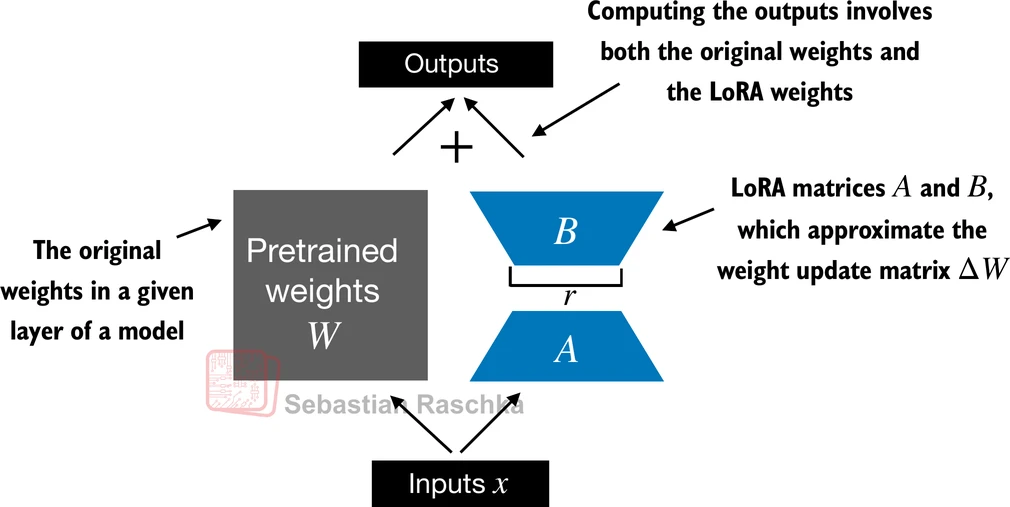
The main advantages are practical:
- fewer trainable parameters
- lower memory requirements during finetuning
- smaller task-specific adapter files
- the same base model can support many lightweight adapters
That is why parameter-efficient finetuning is often preferable when:
- GPU memory is limited
- you want to adapt a model to many tasks cheaply
- you want faster experimentation
- you do not want to store a separate fully finetuned model for every use case
The appendix-E material in the repo shows that this can dramatically reduce the number of trainable parameters while still giving good downstream performance.
However, LoRA is not automatically better in every scenario. Full finetuning can still be preferable when:
- you have enough compute and memory
- the task is large enough to justify full adaptation
- you want the model to change more deeply and broadly
- you need the absolute best task-specific performance and are willing to pay for it
So the tradeoff is usually:
- LoRA: cheaper, lighter, easier to scale across many tasks
- full finetuning: more flexible, but much more resource intensive
Another practical benefit of LoRA is deployment convenience. Because the base model stays frozen, you can often keep one shared base checkpoint and swap in different adapters depending on the task.
In short, LoRA is a low-rank adaptation method that finetunes an LLM by learning small trainable updates instead of changing all original weights, and it is preferable to full finetuning when compute, memory, storage, or iteration speed are the main constraints.