Machine Learning FAQ
What is a KV cache, and why does it make LLM inference faster?
A KV cache is a memory buffer that stores the previously computed key and value tensors inside each attention layer of a decoder-style LLM during text generation.
The reason it helps is simple: autoregressive generation is sequential. After the model generates one new token, it has to predict the next token from a slightly longer prefix. Without caching, it would repeatedly recompute attention keys and values for all earlier tokens at every generation step.
Consider the prompt "Time flies". The first figure highlights the key and value vectors for the existing tokens:
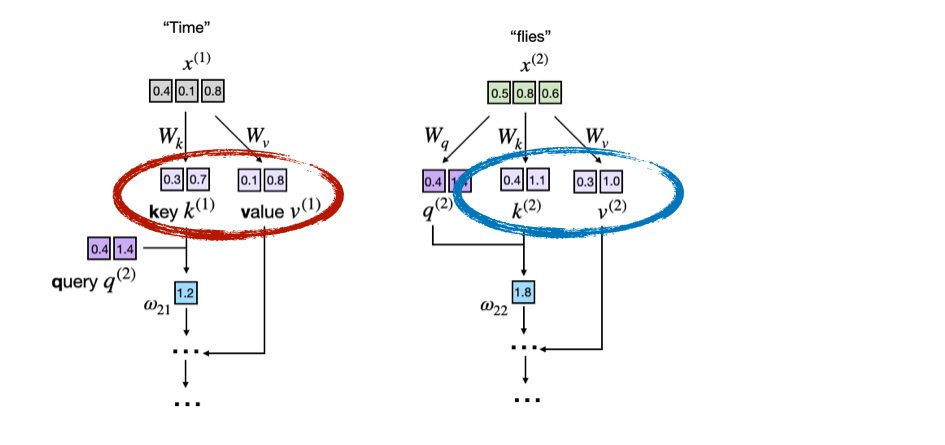
Then, after adding the new token "fast", the model still needs the old keys and values for "Time" and "flies", but those tensors have not changed. Recomputing them is just repeated work:
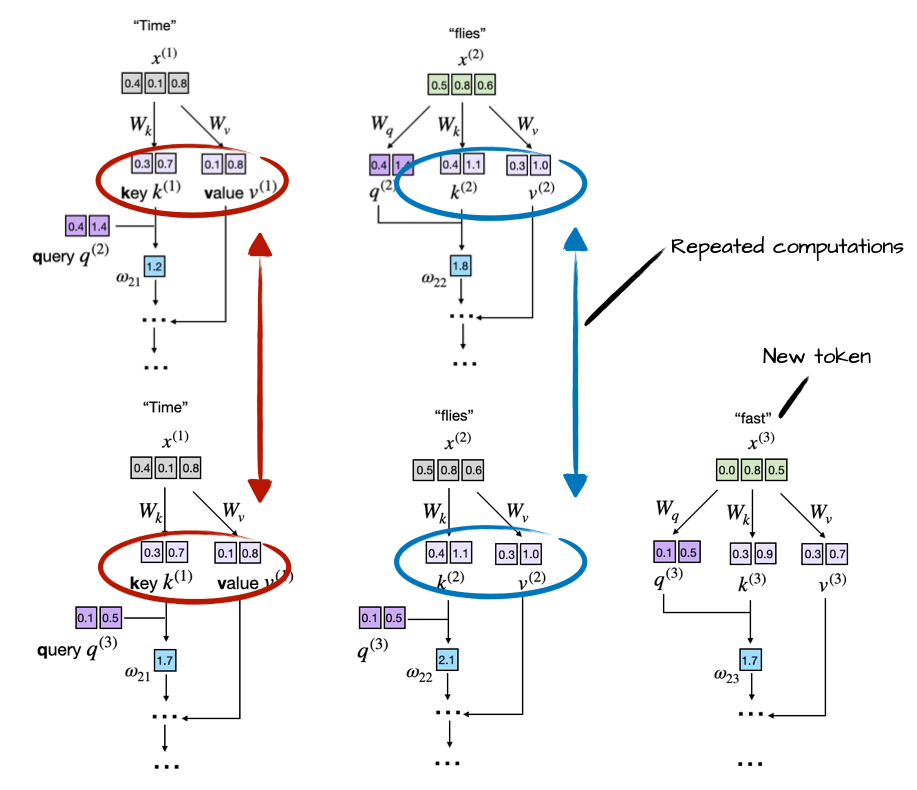
That is the core idea of a KV cache:
- Run the model on the initial prompt and store the keys and values for each layer.
- When a new token is generated, compute keys and values only for that new token.
- Append those new tensors to the existing cache.
- Reuse the cached keys and values when the new token attends to the full prefix.
The following figure shows that caching step explicitly. In the top panel, the model recomputes all earlier key and value vectors. In the bottom panel, the old key and value vectors are pulled from the KV cache, and only the new token contributes new K and V tensors:
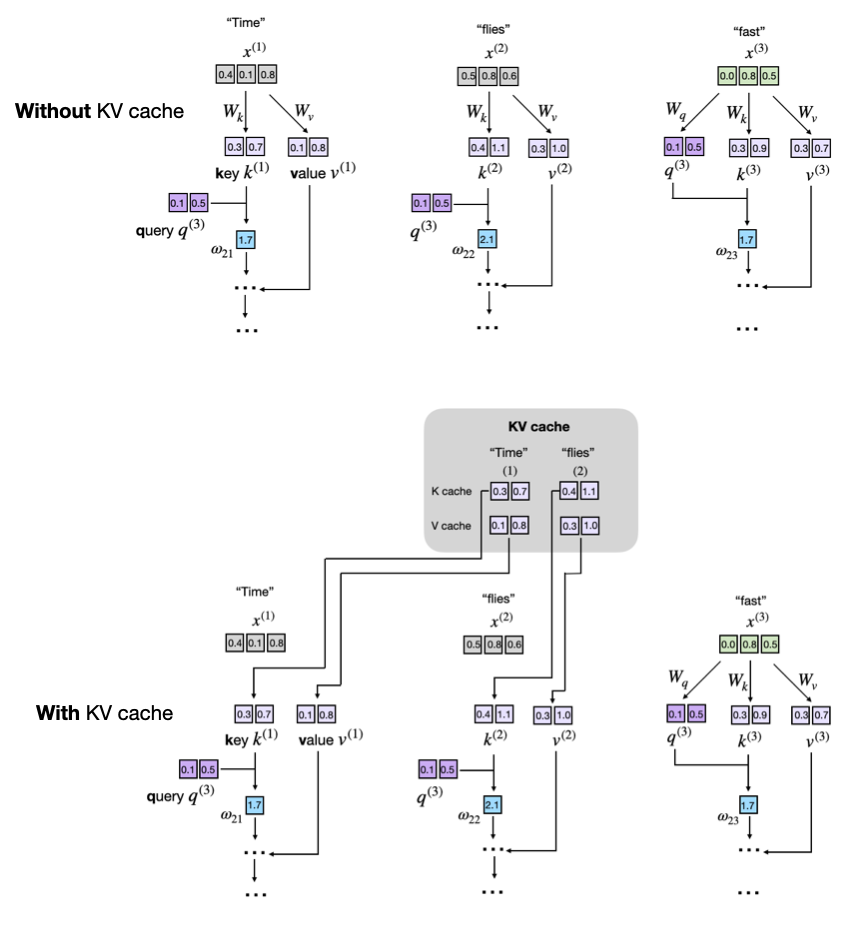
An important detail is that we cache keys and values, not old queries. The model only needs the query of the current token to produce the next logits. Older queries are no longer needed, but older keys and values are still needed because the current token must attend over the whole prefix.
This makes inference faster because the model stops rebuilding the full attention state from scratch at every decoding step. Instead, it incrementally extends the existing state. The benefit grows with sequence length: for very short generations the difference may be small, but for long prompts or long outputs the savings become substantial.
The tradeoff is memory. A KV cache has to keep keys and values for previous tokens around in every layer, so the cache grows with sequence length. In modern LLM serving, that cache is often one of the main memory bottlenecks, which is why techniques such as grouped-query attention, sliding-window attention, and MLA focus heavily on reducing KV-cache cost.
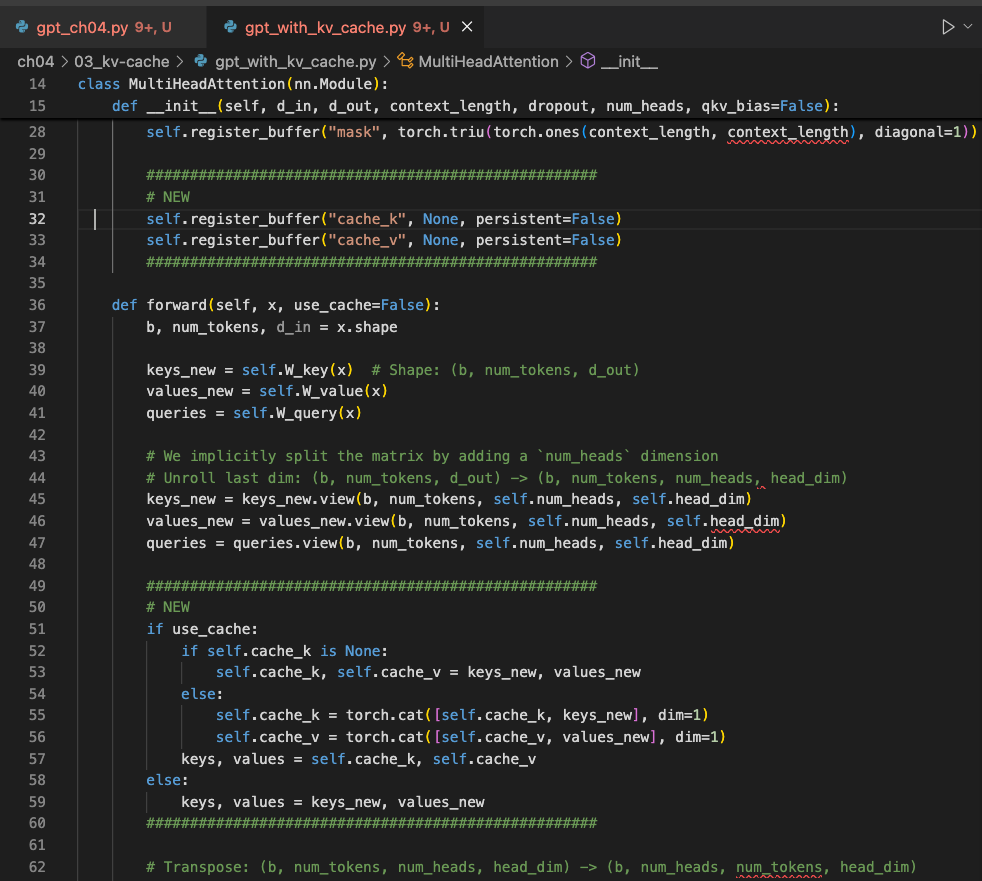
At the implementation level, the idea is exactly what the concept suggests:
- each attention block keeps
cache_kandcache_vbuffers - new token states are appended to those buffers during decoding
- the model resets the cache between independent generation calls
- position indices are tracked so newly decoded tokens line up with the cached prefix
The following screenshot shows those additions directly:
This is also why KV caching is mainly an inference optimization, not a training trick. During training, models process many token positions in parallel, so the computation pattern is different and caching past decoding states is usually not the right optimization.
A good mental model is this: the KV cache lets the model keep the attention state it has already paid to compute, instead of rebuilding that state every time it generates one more token.
In short, a KV cache stores past key and value tensors so an LLM can reuse them during autoregressive decoding, which speeds up inference by avoiding repeated attention computation over the same prefix.