Machine Learning FAQ
How are input-target training examples constructed for LLM pretraining?
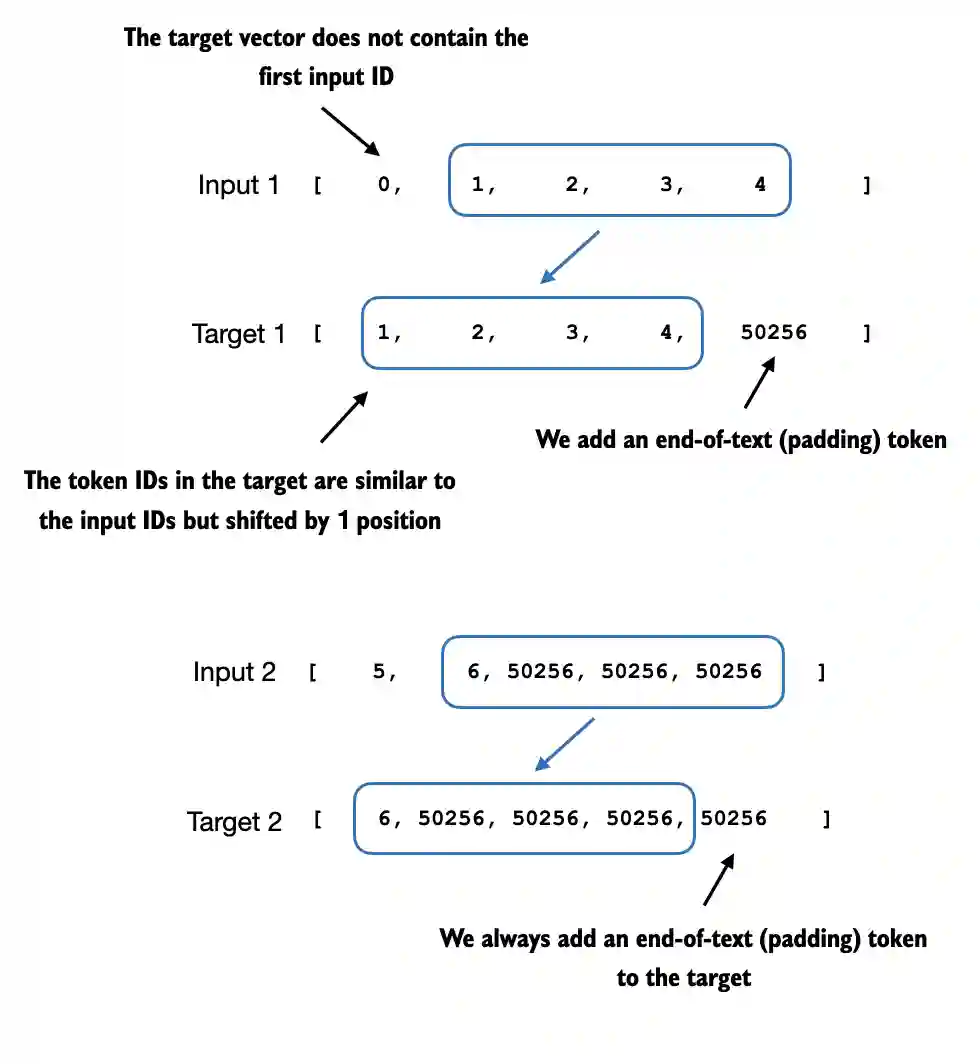
LLM pretraining examples are usually constructed directly from ordinary unlabeled text. After tokenization, the text becomes a long stream of token IDs. From that stream, we create short fixed-length sequences that the model will read as inputs, and the corresponding targets are simply the same sequences shifted one token to the left.
For example, if an input chunk contains
[t1, t2, t3, t4]
then the target chunk is
[t2, t3, t4, t5]
So the model is asked to predict the next token at every position in the sequence.
There are two key steps in practice.
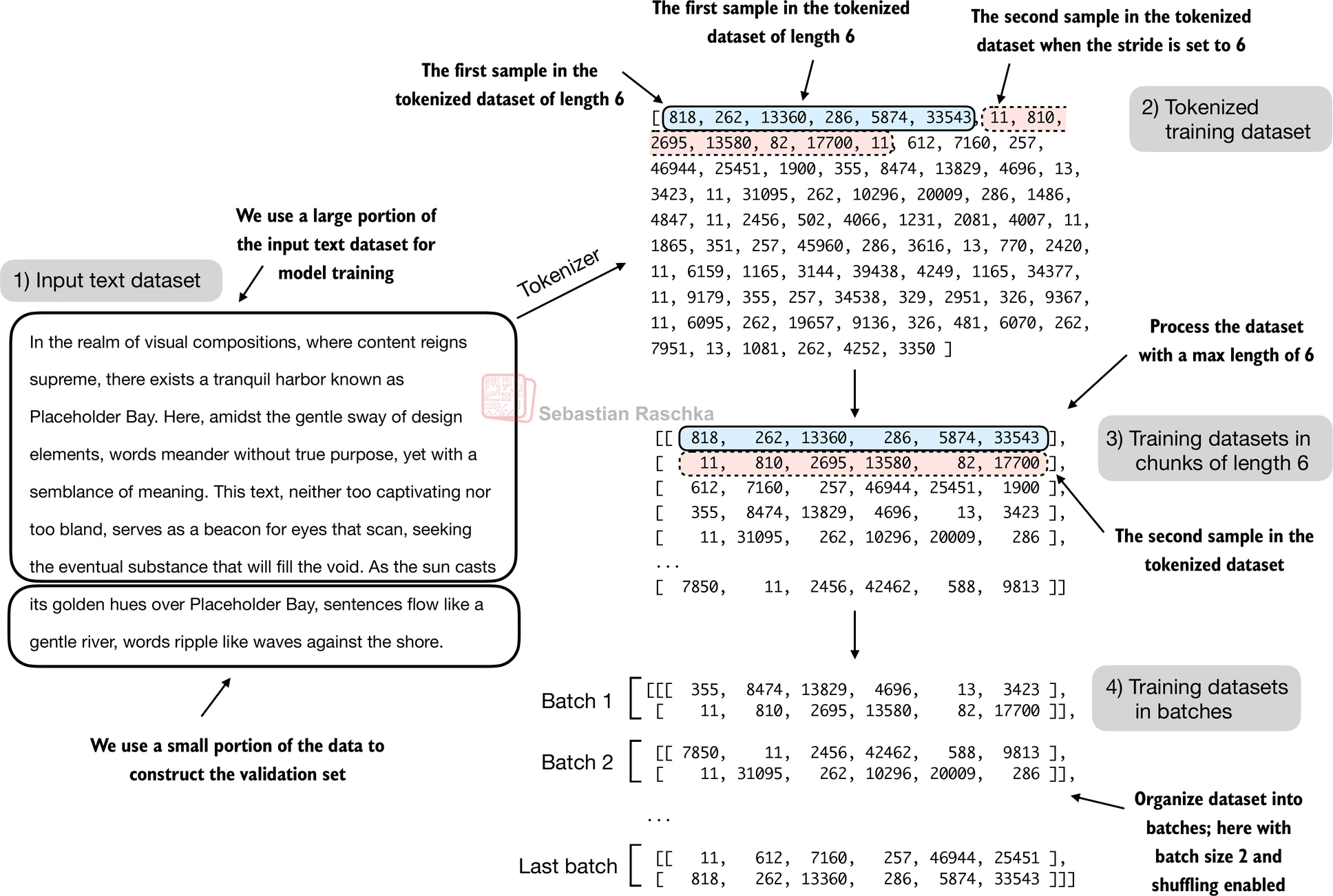
First, we choose a context length, which is the number of tokens per training example. If the context length is 256, then each example contains 256 input tokens and 256 shifted target tokens. This lets the model learn many next-token predictions in parallel from one chunk rather than from a single next-word pair.
Second, we choose a stride, which determines how far we move forward before taking the next chunk. If the stride is small, adjacent examples overlap heavily. If the stride equals the context length, the chunks do not overlap. The chapter 2 dataloader in the repo shows both patterns.

Once these chunks are created, they are grouped into mini-batches so the model can train efficiently on many sequences at once.
This construction is what makes pretraining self-supervised. We do not need humans to label the next token. The text itself already contains the supervision. Every document automatically provides its own training targets.
It is also worth noting what the model is not doing here. It is not shown the full target sequence as a separate answer in the way a classification model is shown a class label. Instead, a GPT-style model reads the input sequence with a causal mask, produces one logits vector per position, and is penalized whenever the correct next token at that position gets too little probability.
So, the recipe is:
- Tokenize a large text corpus into token IDs.
- Slice the token stream into context windows.
- Use each window as the input.
- Use the same window shifted by one token as the target.
- Batch those examples and optimize next-token prediction loss.
In short, pretraining examples for an LLM are constructed by turning raw tokenized text into many fixed-length input chunks, with the targets created by shifting those same chunks by one token so the model learns to predict what comes next.