Machine Learning FAQ
What is grouped-query attention (GQA), and why do many modern LLMs use it?
Grouped-query attention (GQA) is an attention variant where multiple query heads share the same key and value heads.
In standard multi-head attention, every attention head has its own queries, keys, and values. In GQA, the model keeps multiple query heads but reduces the number of distinct key and value heads by grouping them.
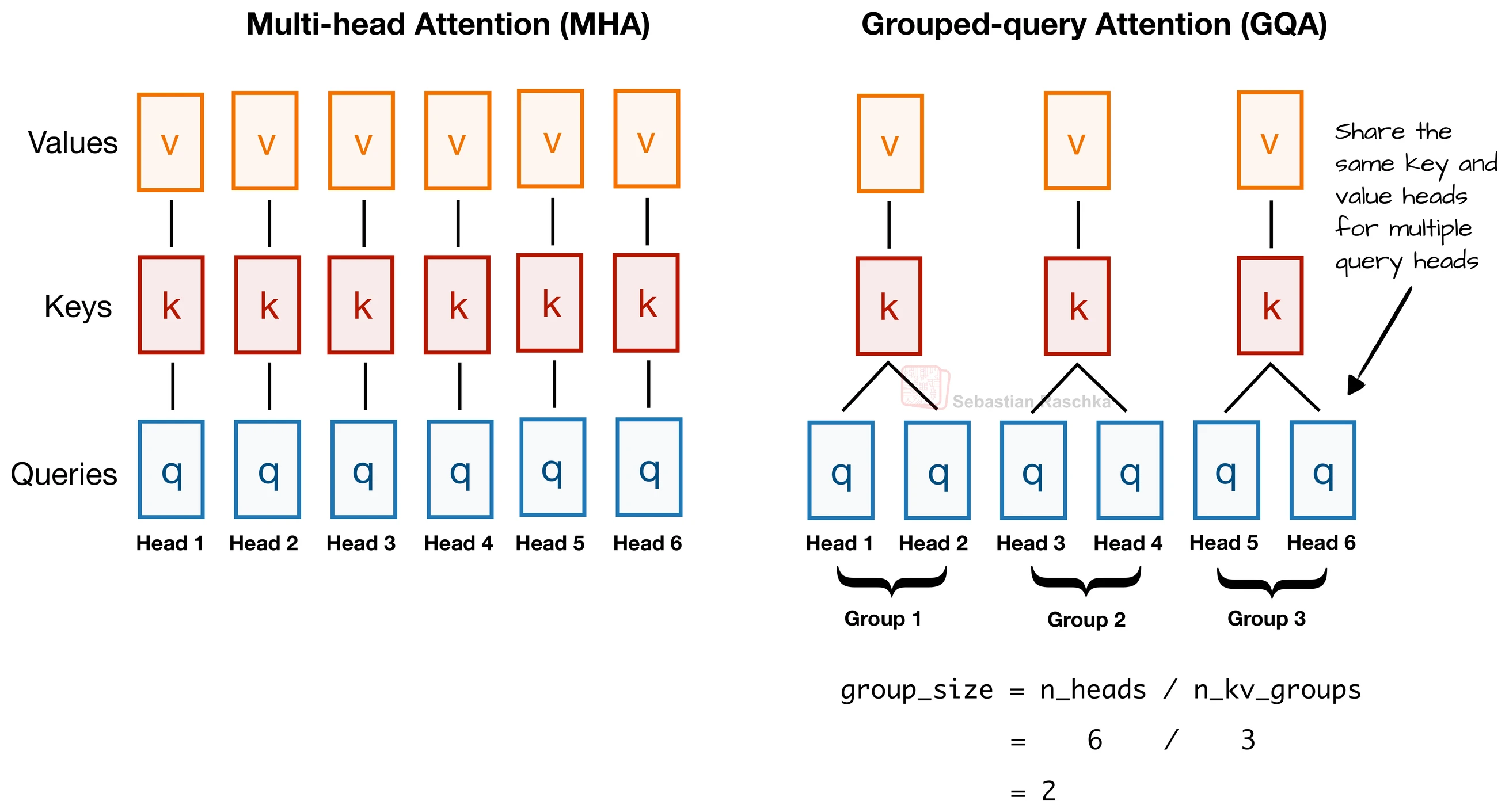
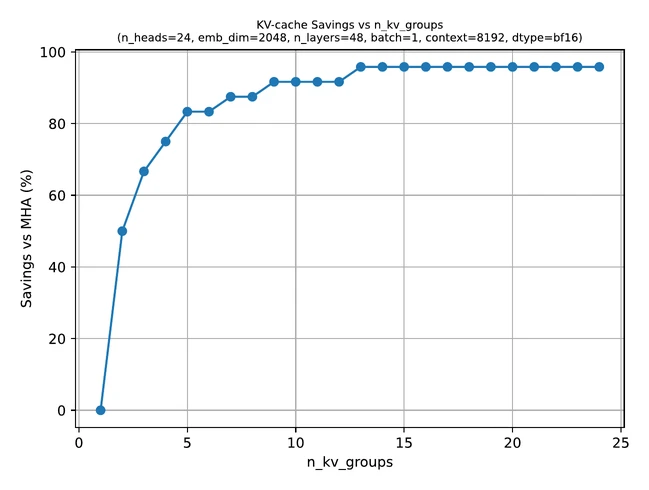
This is useful because keys and values are especially important for inference memory, particularly once a model uses a KV cache. If fewer key and value heads need to be stored, the KV cache becomes much smaller.
That is the main practical reason many modern LLMs use GQA:
- it reduces KV-cache memory
- it lowers memory bandwidth pressure during inference
- it usually preserves model quality much better than more extreme alternatives
The repo’s GQA bonus material summarizes the central tradeoff well. If we reduce key-value heads too aggressively all the way down to one shared key-value set, we get multi-query attention, which saves even more memory but can hurt modeling performance. GQA is the middle ground between standard multi-head attention and that extreme.
Conceptually, GQA says:
- keep multiple query views so the model can still attend in several ways
- share key and value representations across groups of heads to save memory
That is why it is especially attractive in long-context models. As context length grows, KV-cache cost becomes a major bottleneck, and GQA directly attacks that bottleneck.
The repo also notes that modern architectures such as Llama 3, Gemma 3, and Qwen use GQA or closely related attention designs. That reflects a broader industry shift: once models became large enough and contexts long enough, standard multi-head attention became expensive enough that inference efficiency started to matter a lot.
It is important to note that GQA is mainly an engineering optimization, not a completely different modeling philosophy. The model still uses attention and still has multiple heads. The change is specifically about sharing the key and value side more efficiently.
So, at a high level:
- standard MHA gives every head its own Q, K, and V
- GQA gives every query head its own query projection but shares K and V across groups
In short, grouped-query attention is a more memory-efficient version of multi-head attention that keeps multiple query heads while sharing key and value heads, which is why it has become common in modern LLMs that care about fast, long-context inference.