Machine Learning FAQ
What architectural changes turned GPT-style models into Llama-style models?
Llama-style models are not a completely different species from GPT-style models. They keep the same broad decoder-only transformer blueprint, but they modernize several important details.
The repo’s architecture-comparison material shows this progression very clearly.
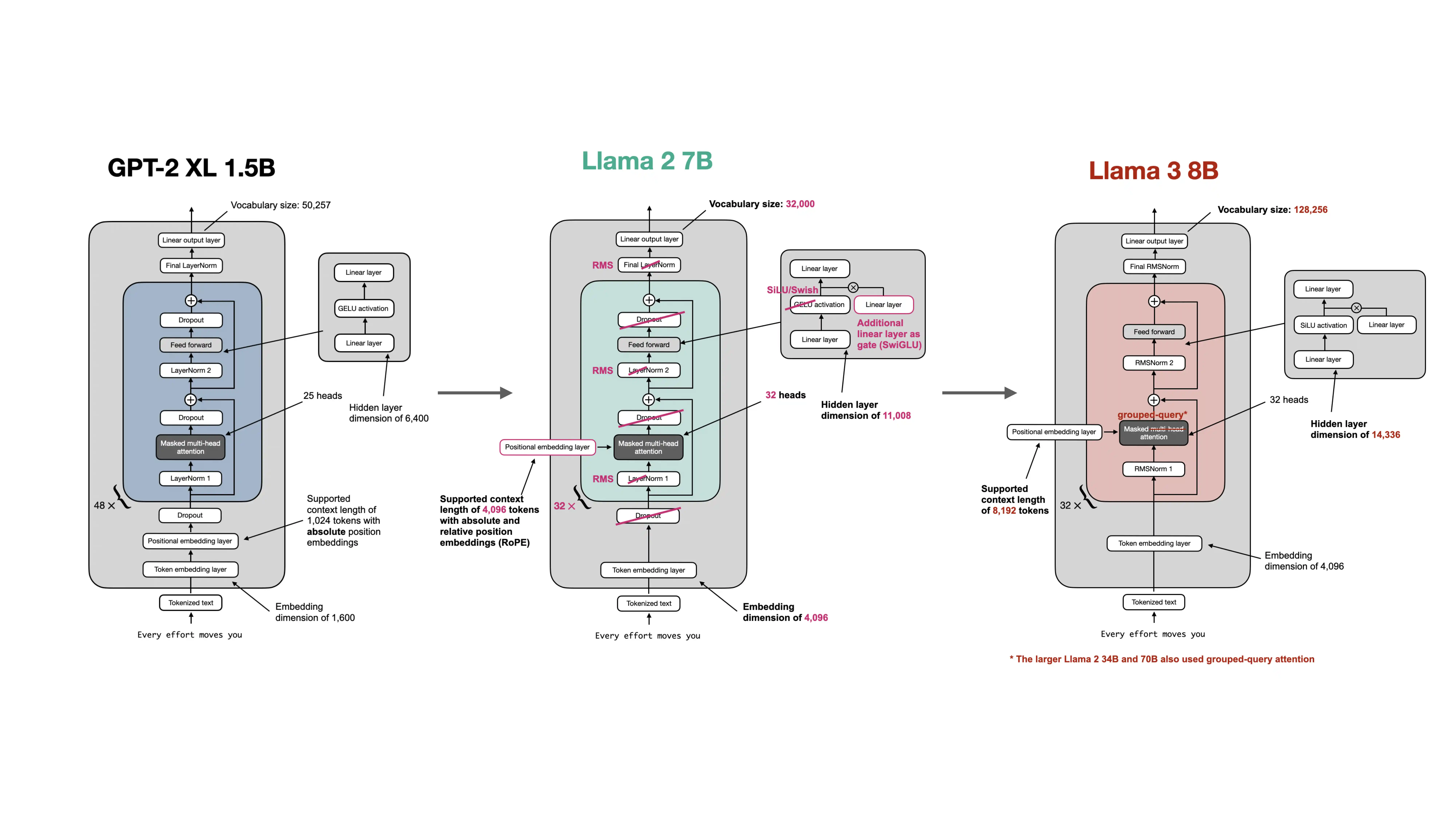
The biggest architectural changes were:
- LayerNorm to RMSNorm
- learned absolute positional embeddings to RoPE
- GELU-style MLPs to SwiGLU feed-forward blocks
- bias-heavy linear layers to largely bias-free linear layers
Later Llama-family variants and related modern families also adopted more inference-efficient attention patterns such as GQA.
What did not change is just as important:
- still decoder-only
- still autoregressive next-token prediction
- still built from stacked transformer blocks with residual connections
So the move from GPT-style to Llama-style was more of a modernization of the same core recipe than a total reinvention.
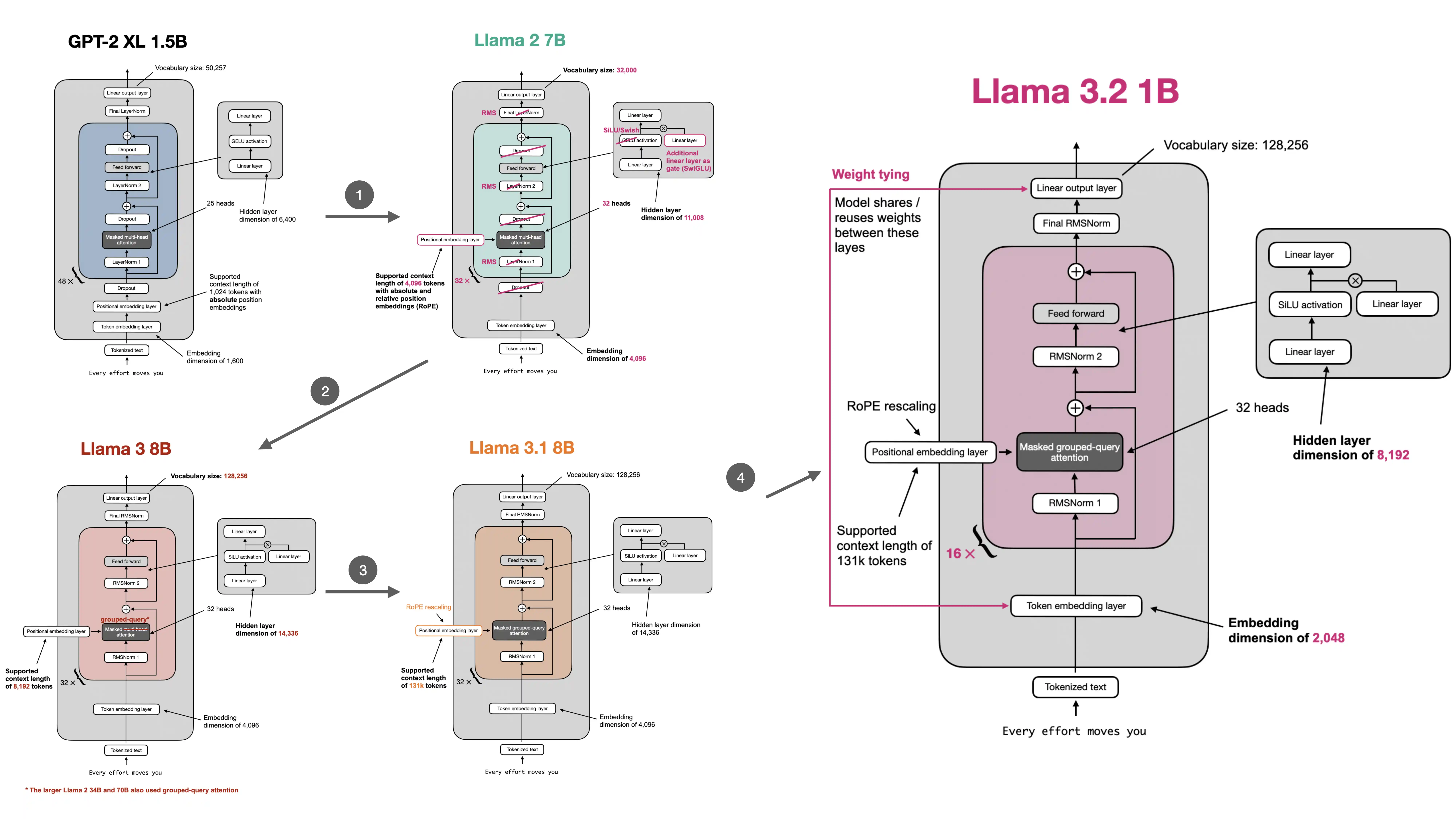
This is why people often describe modern open LLM architecture as a sequence of pragmatic refinements:
- keep what already works
- replace expensive or weaker subcomponents
- improve inference efficiency where long-context serving hurts most
In short, GPT-style models turned into Llama-style models not by abandoning the decoder-only transformer, but by updating its normalization, positional encoding, feed-forward design, bias usage, and attention efficiency choices.