Machine Learning FAQ
What are the main building blocks of a GPT-style model?
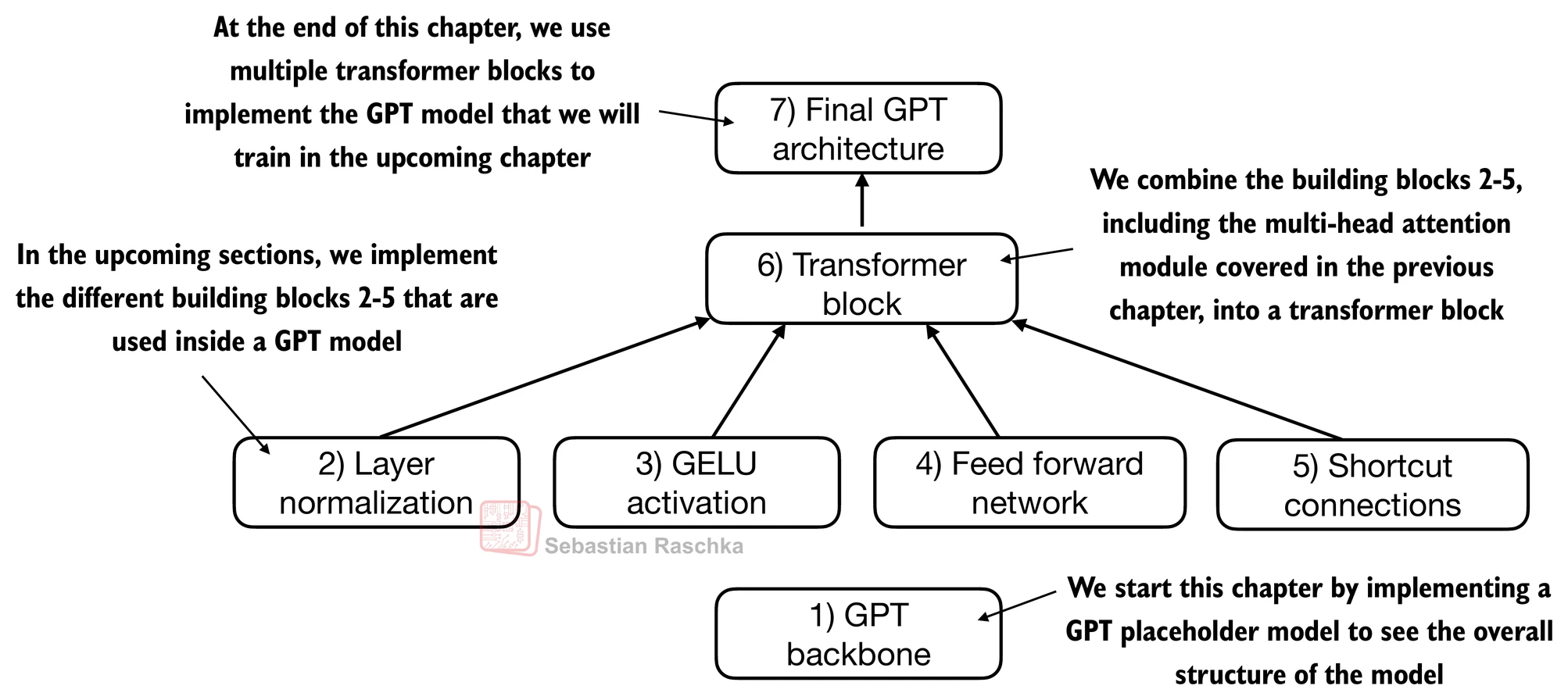
A GPT-style model is built from a small number of repeating components that work together to turn token IDs into next-token predictions.
At the highest level, the pipeline looks like this:
- Tokenize text into token IDs.
- Convert token IDs into embeddings.
- Add positional information.
- Pass the resulting sequence through a stack of transformer blocks.
- Apply a final normalization layer.
- Project each token representation to vocabulary logits with an output head.
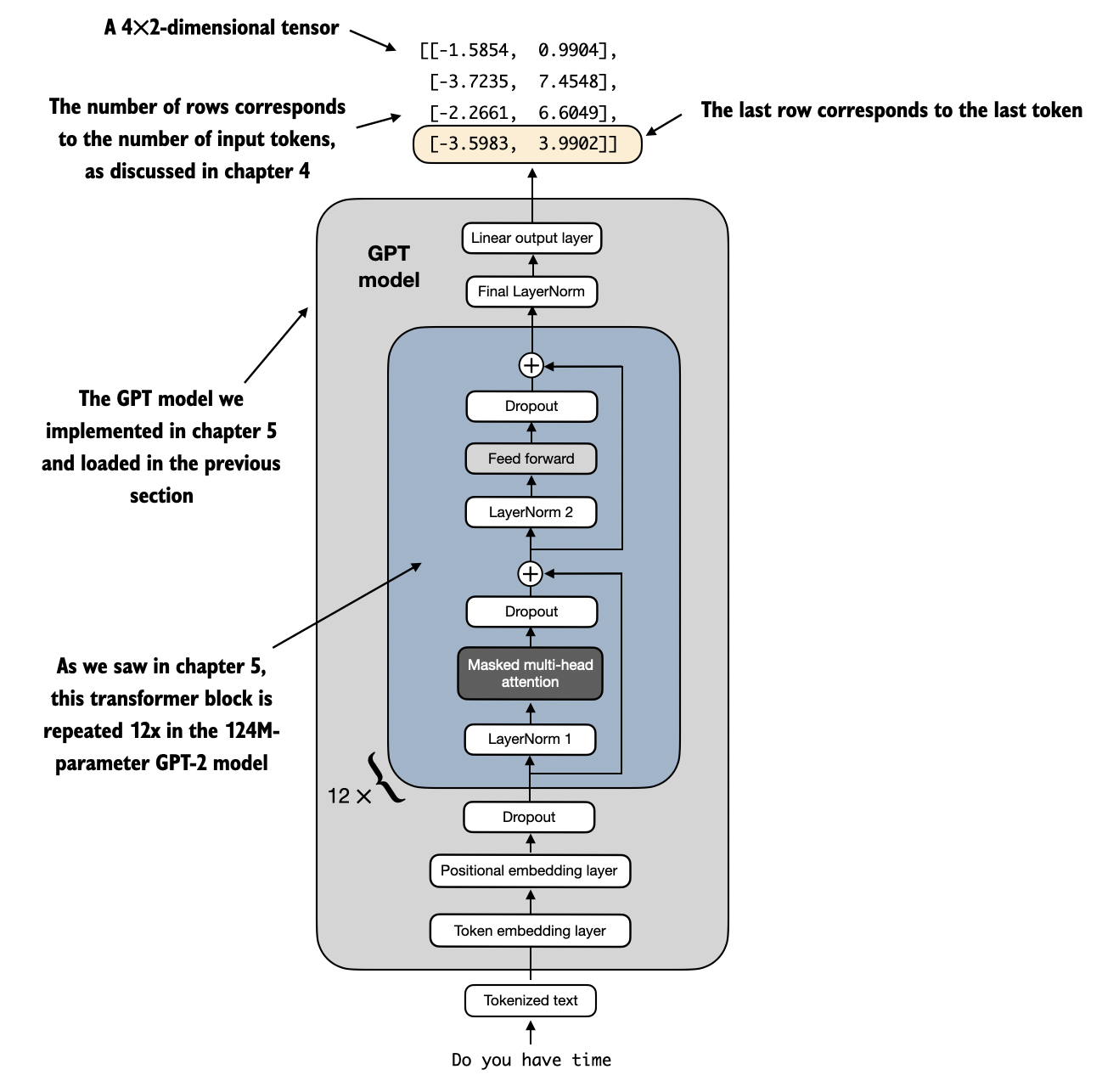
The main building blocks are the following.
1. Token embeddings
These map discrete token IDs into dense vectors. The model does not operate directly on raw token IDs. It operates on learned continuous representations.
2. Positional embeddings or positional encoding
These tell the model where each token sits in the sequence so that word order is preserved.
3. Transformer blocks
This is the core repeated module. A GPT model usually stacks many identical transformer blocks on top of one another. Each block refines the sequence representations, and the whole stack is what makes the model deep rather than just a single attention layer.
4. Causal self-attention
Inside each transformer block, self-attention lets each token gather information from earlier tokens in the prefix. The causal mask ensures the model cannot look at future tokens.
5. Feed-forward network
After attention, each token is passed through a position-wise multilayer perceptron. This gives the model extra nonlinear capacity beyond the token-to-token mixing done by attention.
6. Layer normalization
Normalization stabilizes training and keeps activations in a workable range across many layers.
7. Residual or shortcut connections
Residual paths add the input of a sublayer back to its output. This helps optimization and supports stable deep networks.
In the simple GPT implementation from the repo, each transformer block contains two main sublayers:
- a masked multi-head attention module
- a feed-forward module
and each of those is wrapped with normalization and residual connections.
The final output head is usually a linear layer that maps the final hidden representation at each position to one score per vocabulary token. Those scores are the logits used for next-token prediction.
An important point is that GPT is a decoder-only transformer. That means it uses the autoregressive, causal form of attention intended for text generation. It does not include the separate encoder-decoder structure used in sequence-to-sequence transformers such as the original translation model.
So, while large modern LLMs add many refinements, the core GPT recipe is remarkably compact:
- embeddings
- positional information
- repeated transformer blocks
- final normalization
- vocabulary projection
In short, a GPT-style model is mainly a stack of causal transformer blocks sitting between an input embedding stage and a final output layer that predicts the next token.