Machine Learning FAQ
Why is full finetuning so expensive compared with LoRA?
Full finetuning is so expensive compared with LoRA because it updates all of the model’s trainable weights, not just a small adapter.
That means full finetuning has to carry the cost of:
- gradients for the whole model
- optimizer states for the whole model
- larger checkpoint outputs
- more memory bandwidth during training
By contrast, LoRA freezes the base model and learns only a low-rank update on selected linear layers.
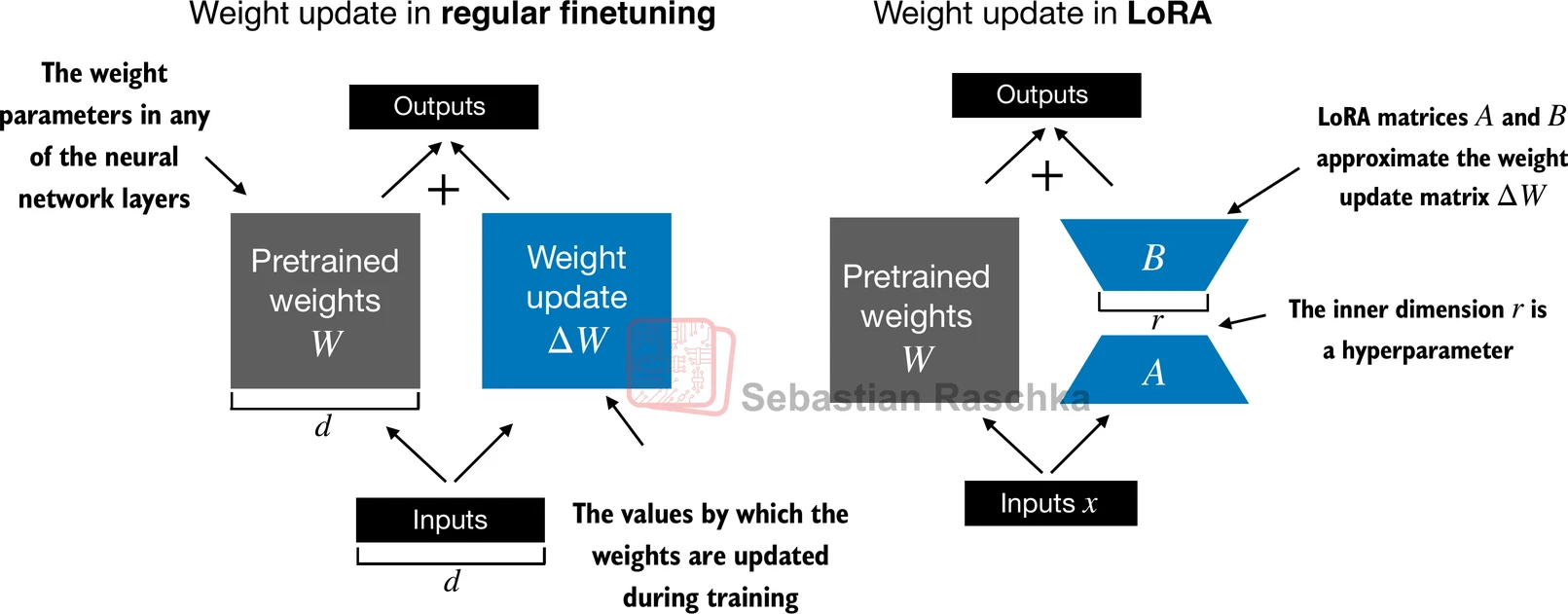
This difference becomes dramatic at LLM scale. Even if the base model is the same, the training burden changes a lot depending on whether you update billions of original parameters or only a relatively small number of adapter parameters.
That is why LoRA is often cheaper in several ways at once:
- lower VRAM usage
- fewer trainable parameters
- smaller task-specific files
- faster iteration over multiple experiments
The repo’s appendix-E material also shows how LoRA can be applied across a model without replacing the frozen pretrained checkpoint itself.
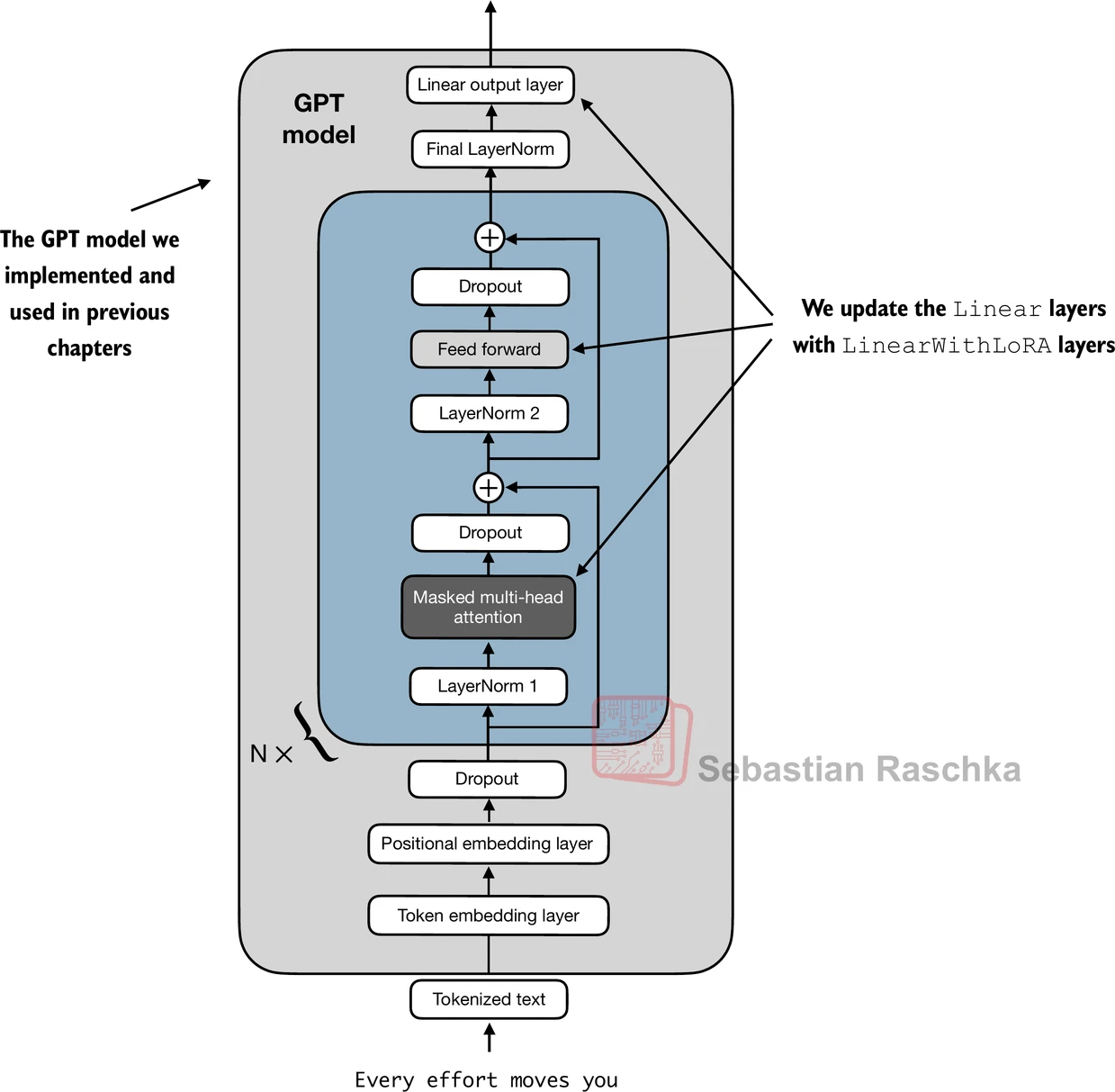
So the main reason full finetuning is expensive is not just parameter count in the abstract. It is that training every weight creates a much larger end-to-end optimization problem in memory, compute, and storage.
In short, full finetuning is much more expensive than LoRA because it updates every parameter and all related optimizer state, while LoRA keeps the base model frozen and learns only small low-rank adapters.