Machine Learning FAQ
When should you use exact-match metrics versus LLM-as-a-judge evaluation?
You should use exact-match metrics when the task has a narrow, clearly defined target, and use LLM-as-a-judge evaluation when the task is open-ended enough that many different answers could be acceptable.
Exact match works well for tasks such as:
- classification labels
- short factual answers with one canonical form
- structured extraction
- tasks where unit tests or strict string checks make sense
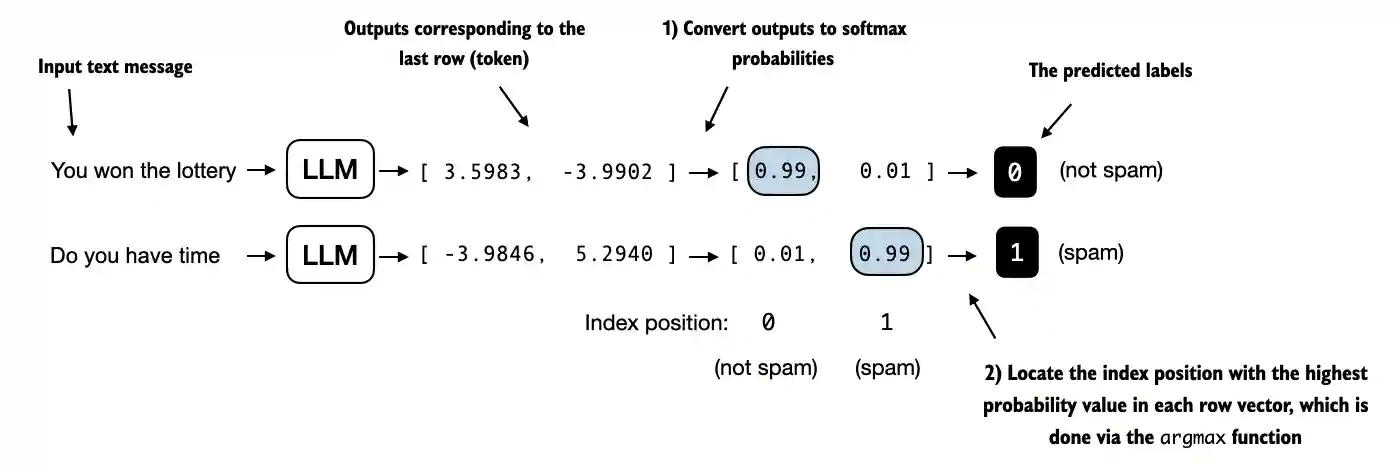
In those cases, exact match is attractive because it is:
- cheap
- reproducible
- easy to interpret
But exact match breaks down once the task becomes more open-ended. Two answers can differ in wording and still both be correct and useful.
That is where LLM-as-a-judge becomes useful. Instead of comparing to one exact reference string, you ask a stronger model to score or compare responses based on quality criteria such as correctness, helpfulness, and instruction adherence.
So the practical rule is:
- use exact match when correctness is narrow and objectively checkable
- use LLM-as-a-judge when good answers can vary in wording or style
The two can also be combined. For example, you might use exact match for a strict subset of tasks and judge-based scoring for the rest. And for important evaluations, human spot checks are still valuable because judge models can have their own biases.
In short, exact-match metrics are best when the answer space is narrow and deterministic, while LLM-as-a-judge evaluation is better when response quality is open-ended and cannot be captured by one reference string.