Machine Learning FAQ
Why can an embedding layer be interpreted as a linear layer applied to one-hot encoded tokens?
An embedding layer can be interpreted as a linear layer applied to one-hot encoded tokens because both operations return the same learned vector for a given token identity.
Suppose the vocabulary size is denoted by \(V\) and the embedding dimension by \(d\). Then an embedding layer stores a matrix
\[E \in \mathbb{R}^{V \times d}.\]If a token has index \(i\), the embedding layer simply returns the \(i\)-th row of that matrix. In other words, an embedding layer is a learned lookup table.
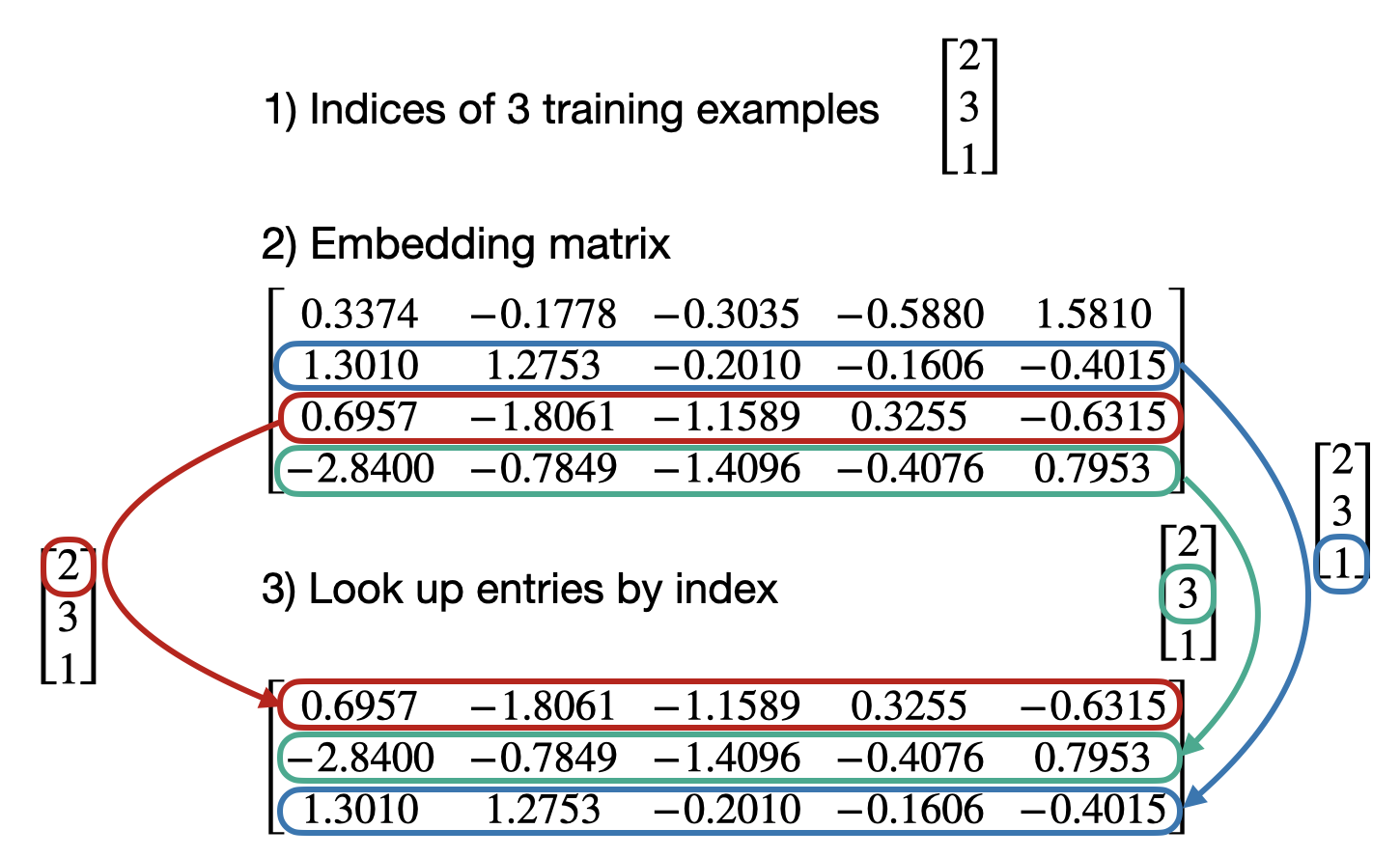
Now represent the same token index \(i\) as a one-hot vector. In symbols:
\[e_i \in \mathbb{R}^{V}.\]All entries are zero except for a single 1 at position \(i\). If we multiply this one-hot vector by the embedding matrix, we get
\[e_i^\top E = E_i,\]which is again exactly the \(i\)-th row of the embedding matrix. The reason is simple: all rows are multiplied by 0 except the selected row, which is multiplied by 1.
For a batch of tokens, the same idea holds. A stack of one-hot vectors multiplied by the embedding matrix produces the same batch of embedding vectors that an embedding lookup would return:
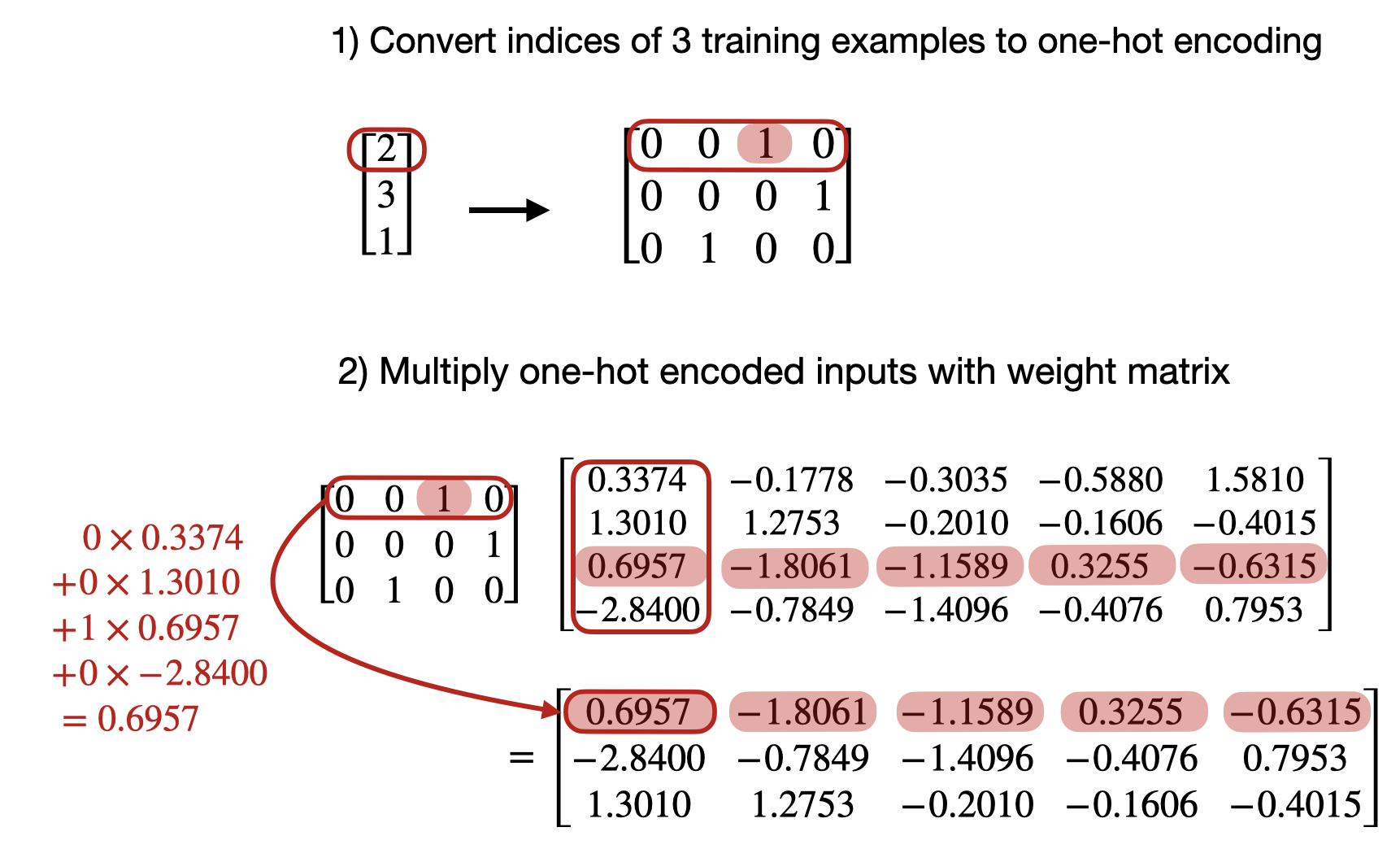
So mathematically, an embedding layer and a bias-free linear layer on one-hot inputs are equivalent. In framework implementations, the weight tensor may be stored with a transposed shape depending on the API, but the underlying operation is the same: select or compute the row corresponding to the token identity.
The reason we usually use an actual embedding layer instead of a linear layer on one-hot vectors is efficiency. One-hot vectors are extremely sparse and usually very large because their length equals the vocabulary size. Materializing them and multiplying them with a matrix would waste memory and computation. An embedding layer performs the equivalent operation much more directly as a row-gather or lookup.
In short, the embedding layer is not doing something fundamentally different from a linear layer on one-hot vectors. It is the same mapping written in a more efficient form.