Machine Learning FAQ
What is causal attention, and why can GPT-style models not look at future tokens?
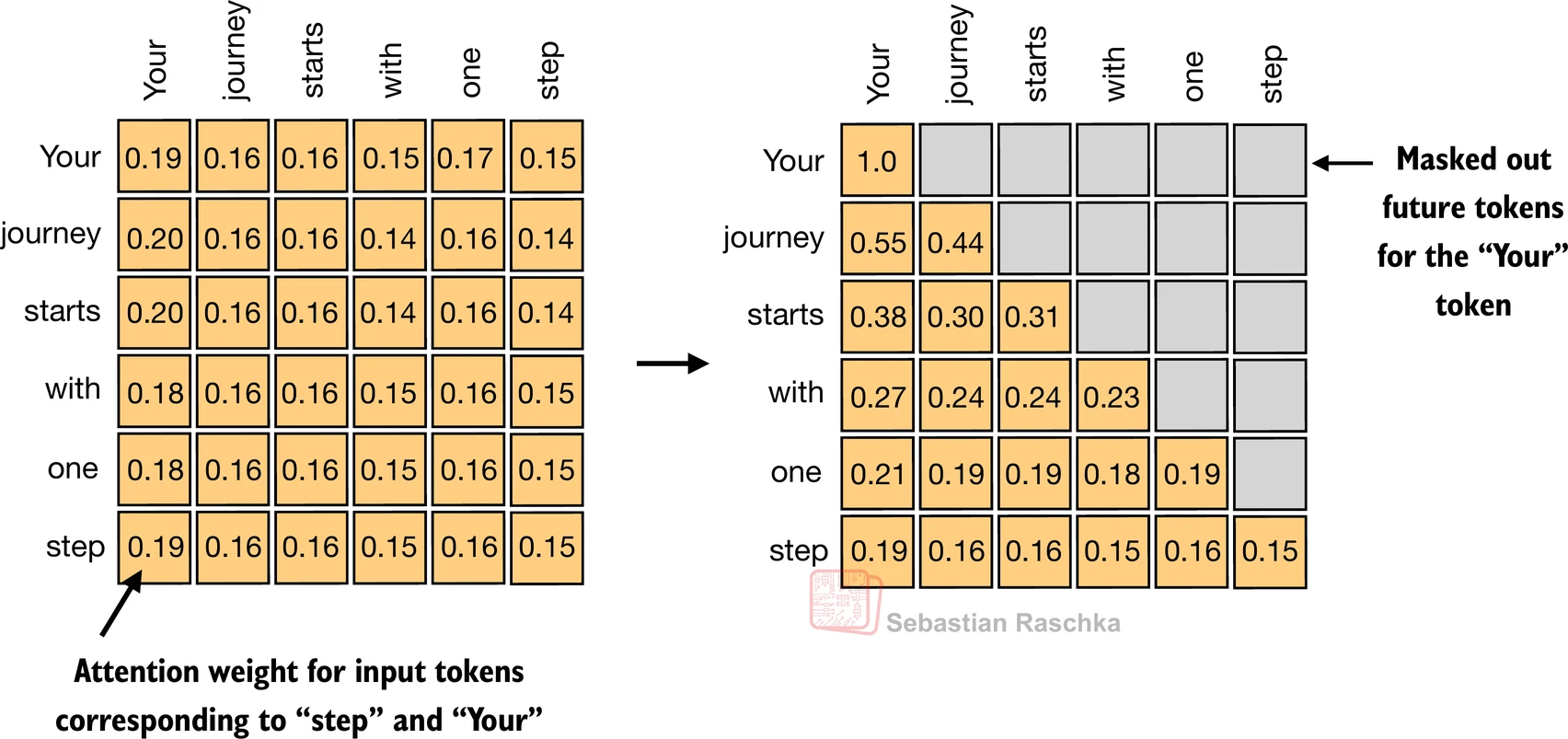
Causal attention is a masked form of self-attention in which each token is allowed to attend only to itself and to earlier tokens, but not to later ones.
In other words, when a GPT-style model is predicting the token at position t, it can use information from positions 1 through t, but it cannot look at positions after t.
This restriction is essential because GPT models are trained for left-to-right next-token prediction. During actual generation, the future tokens do not exist yet. The model only has the prompt and whatever it has generated so far. So the training setup must match that inference setup.
If the model were allowed to look at future tokens during training, the task would become artificially easy. To predict the next token, it could partially peek at the answer. That would create a mismatch:
- Training would let the model use information it will not have later.
- Inference would remove that information.
- Performance would suffer because the model learned under unrealistic conditions.
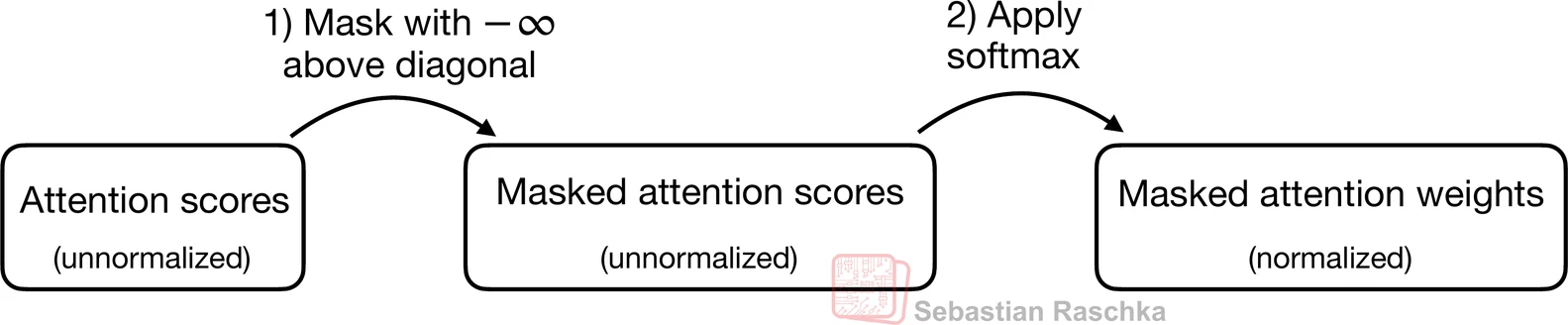
That is why GPT-style models use a causal mask. In practice, the mask is applied inside the attention score matrix before the softmax step. Future positions are set to values such as negative infinity so that, after softmax, their attention weight becomes zero.
This design has an important consequence: every output position is trained as if it were a real next-token prediction problem. The representation for token 5 can depend on tokens 1 through 5, but not on tokens 6 and beyond. That makes the learned computation compatible with autoregressive generation.
It also explains why the last token in a GPT-style sequence often contains the richest summary of the full prefix. Earlier tokens cannot see as much context, but later tokens can accumulate information from more preceding positions.
This is different from transformer encoders such as BERT, where bidirectional attention is allowed. In that setting, a token can attend to tokens on both sides because the training objective is different. GPT is not built that way because it is designed to generate text one token at a time.
So when people say GPT models “cannot look at the future,” they do not mean the model is incapable of representing long-range dependencies. They mean the architecture intentionally blocks access to future positions to preserve the proper left-to-right generation rule.
In short, causal attention is self-attention with a future-token mask, and GPT-style models use it because next-token prediction and autoregressive generation only make sense if the model never cheats by peeking ahead.