Machine Learning Q and AI
30 Essential Questions and Answers on Machine Learning and AI
By Sebastian Raschka. Free to read.
Published by No Starch Press.
Copyright © 2024-2025 by Sebastian Raschka.

Machine learning and AI are moving at a rapid pace. Researchers and practitioners are constantly struggling to keep up with the breadth of concepts and techniques. This book provides bite-sized bits of knowledge for your journey from machine learning beginner to expert, covering topics from various machine learning areas. Even experienced machine learning researchers and practitioners will encounter something new that they can add to their arsenal of techniques.
📘 Print Book:
Amazon
No Starch Press
📄 Read Online:
Full Book (Free)
Chapter 22: Speeding Up Inference
What are techniques to speed up model inference through optimization without changing the model architecture or sacrificing accuracy?
In machine learning and AI, model inference refers to making predictions or generating outputs using a trained model. The main general techniques for improving model performance during inference include parallelization, vectorization, loop tiling, operator fusion, and quantization, which are discussed in detail in the following sections.
Parallelization
One common way to achieve better parallelization during inference is to run the model on a batch of samples rather than on a single sample at a time. This is sometimes also referred to as batched inference and assumes that we are receiving multiple input samples or user inputs simultaneously or within a short time window, as illustrated in Figure 1.1.
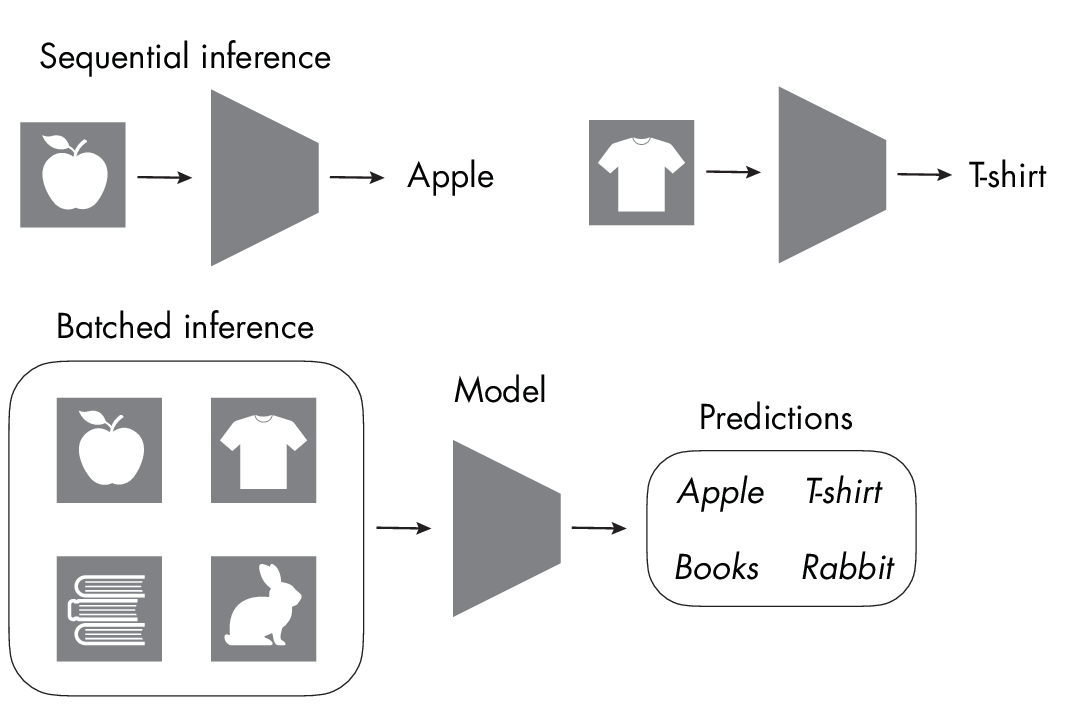
Figure 1.1 shows sequential inference processing one item at a time, which creates a bottleneck if there are several samples waiting to be classified. In batched inference, the model processes all four samples at the same time.
Vectorization
Vectorization refers to performing operations on entire data
structures, such as arrays (tensors) or matrices, in a single step
rather than using iterative constructs like for loops. Using
vectorization, multiple operations from the loop are performed
simultaneously using single instruction, multiple data (SIMD)
processing, which is available on most modern CPUs.
This approach takes advantage of the low-level optimizations in many computing systems and often results in significant speedups. For example, it might rely on BLAS.
BLAS (which is short for Basic Linear Algebra Subprograms) is a specification that prescribes a set of low-level routines for performing common linear algebra operations such as vector addition, scalar multiplication, dot products, matrix multiplication, and others. Many array and deep learning libraries like NumPy and PyTorch use BLAS under the hood.
To illustrate vectorization with an example, suppose we wanted to
compute the dot product between two vectors. The non-vectorized way of
doing this would be to use a for loop, iterating over each element of
the array one by one. However, this can be quite slow, especially for
large arrays. With vectorization, you can perform the dot product
operation on the entire array at once, as shown in
Figure 1.2.

product computation in Python
In the context of linear algebra or deep learning frameworks like TensorFlow and PyTorch, vectorization is typically done automatically. This is because these frameworks are designed to work with multidimensional arrays (also known as tensors), and their operations are inherently vectorized. This means that when you perform functions using these frameworks, you automatically leverage the power of vectorization, resulting in faster and more efficient computations.
Loop Tiling
Loop tiling (also often referred to as loop nest optimization) is an advanced optimization technique to enhance data locality by breaking down a loop’s iteration space into smaller chunks or “tiles.” This ensures that once data is loaded into cache, all possible computations are performed on it before the cache is cleared.
Figure 1.3 illustrates the concept of loop
tiling for accessing elements in a two-dimensional array. In a regular
for loop, we iterate over columns and rows one element at a time,
whereas in loop tiling, we subdivide the array into smaller tiles.
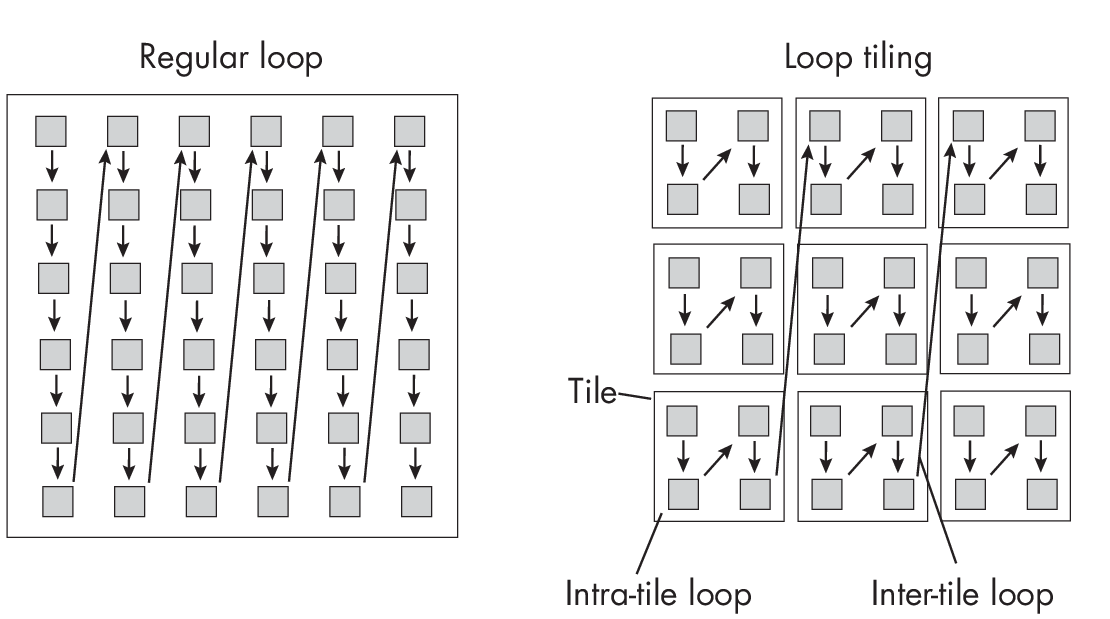
Note that in languages such as Python, we don’t usually perform loop tiling, because Python and many other high-level languages do not allow control over cache memory like lower-level languages such as C and C++ do. These kinds of optimizations are often handled by underlying libraries like NumPy and PyTorch when performing operations on large arrays.
Operator Fusion
Operator fusion, sometimes called loop fusion, is an optimization technique that combines multiple loops into a single loop. This is illustrated in Figure 1.4, where two separate loops to calculate the sum and the product of an array of numbers are fused into a single loop.

Operator fusion can improve the performance of a model by reducing the
overhead of loop control, decreasing memory access times by improving
cache performance, and possibly enabling further optimizations through
vectorization. You might think this behavior of vectorization would be
incompatible with loop tiling, in which we break a for loop into
multiple loops. However, these techniques are actually complementary,
used for different optimizations, and applicable in different
situations. Operator fusion is about reducing the total number of loop
iterations and improving data locality when the entire data fits into
cache. Loop tiling is about improving cache utilization when dealing
with larger multidimensional arrays that do not fit into cache.
Related to operator fusion is the concept of reparameterization, which can often also be used to simplify multiple operations into one. Popular examples include training a network with multibranch architectures that are reparameterized into single-stream architectures during inference. This reparameterization approach differs from traditional operator fusion in that it does not merge multiple operations into a single operation. Instead, it rearranges the operations in the network to create a more efficient architecture for inference. In the so-called RepVGG architecture, for example, each branch during training consists of a series of convolutions. Once training is complete, the model is reparameterized into a single sequence of convolutions.
Quantization
Quantization reduces the computational and storage requirements of machine learning models, particularly deep neural networks. This technique involves converting the floating-point numbers (technically discrete but representing continuous values within a specific range) for implementing weights and biases in a trained neural network to more discrete, lower- precision representations such as integers. Using less precision reduces the model size and makes it quicker to execute, which can lead to significant improvements in speed and hardware efficiency during inference.
In the realm of deep learning, it has become increasingly common to quantize trained models down to 8-bit and 4-bit integers. These techniques are especially prevalent in the deployment of large language models.
There are two main categories of quantization. In post-training quantization, the model is first trained normally with full-precision weights, which are then quantized after training. Quantization-aware training, on the other hand, introduces the quantization step during the training process. This allows the model to learn to compensate for the effects of quantization, which can help maintain the model’s accuracy.
However, it’s important to note that quantization can occasionally lead to a reduction in model accuracy. Since this chapter focuses on techniques to speed up model inference without sacrificing accuracy, quantization is not as good a fit for this chapter as the previous categories.
Exercises
22-1. Chapter [ch07] covered several multi-GPU training paradigms to speed up modeltraining.UsingmultipleGPUscan,intheory,alsospeedupmodel inference. However, in reality, this approach is often not the most efficient or most practical option. Why is that?
22-2. Vectorization and loop tiling are two strategies for optimizing operations that involve accessing array elements. What would be the ideal situation in which to use each?
References
-
The official BLAS website: https://www.netlib.org/blas/.
-
The paper that proposed loop tiling: Michael Wolfe, “More Iteration Space Tiling” (1989), https://dl.acm.org/doi/abs/10.1145/76263.76337.
-
RepVGG CNN architecture merging operations in inference mode: Xiaohan Ding et al., “RepVGG: Making VGG-style ConvNets Great Again” (2021), https://arxiv.org/abs/2101.03697.
-
A new method for quantizing the weights in large language mod- els downto8-bitintegerrepresentations:TimDettmersetal., “LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale” (2022), https://arxiv.org/abs/2208.07339.
-
A new method for quantizing the weights in LLMs farther down to 4-bit integers: Elias Frantar et al., “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers” (2022), https://arxiv.org/abs/2210.17323.
Support the Author
You can support the author in the following ways:
- Subscribe to Sebastian's Substack blog
- Purchase a copy on Amazon or No Starch Press
- Write an Amazon review