Machine Learning Q and AI
30 Essential Questions and Answers on Machine Learning and AI
By Sebastian Raschka. Free to read.
Published by No Starch Press.
Copyright © 2024-2025 by Sebastian Raschka.

Machine learning and AI are moving at a rapid pace. Researchers and practitioners are constantly struggling to keep up with the breadth of concepts and techniques. This book provides bite-sized bits of knowledge for your journey from machine learning beginner to expert, covering topics from various machine learning areas. Even experienced machine learning researchers and practitioners will encounter something new that they can add to their arsenal of techniques.
📘 Print Book:
Amazon
No Starch Press
📄 Read Online:
Full Book (Free)
Chapter 21: Data-Centric AI
What is data-centric AI, how does it compare to the conventional modeling paradigm, and how do we decide whether it’s the right fit for a project?
Data-centric AI is a paradigm or workflow in which we keep the mo- del training procedure fixed and iterate over the dataset to improve the predictive performance of a model. The following sections define what data-centric AI means in more detail and compare it to conventional model-centric approaches.
Data-Centric vs. Model-Centric AI
In the context of data-centric AI, we can think of the conventional workflow, which is often part of academic publishing, as model-centric AI. However, in an academic research setting, we are typically interested in developing new methods (for example, neural network architectures or loss functions). Here, we consider existing benchmark datasets to compare the new method to previous approaches and determine whether it is an improvement over the status quo.
Figure [fig:ch21-fig01] summarizes the difference between data-centric and model-centric workflows.
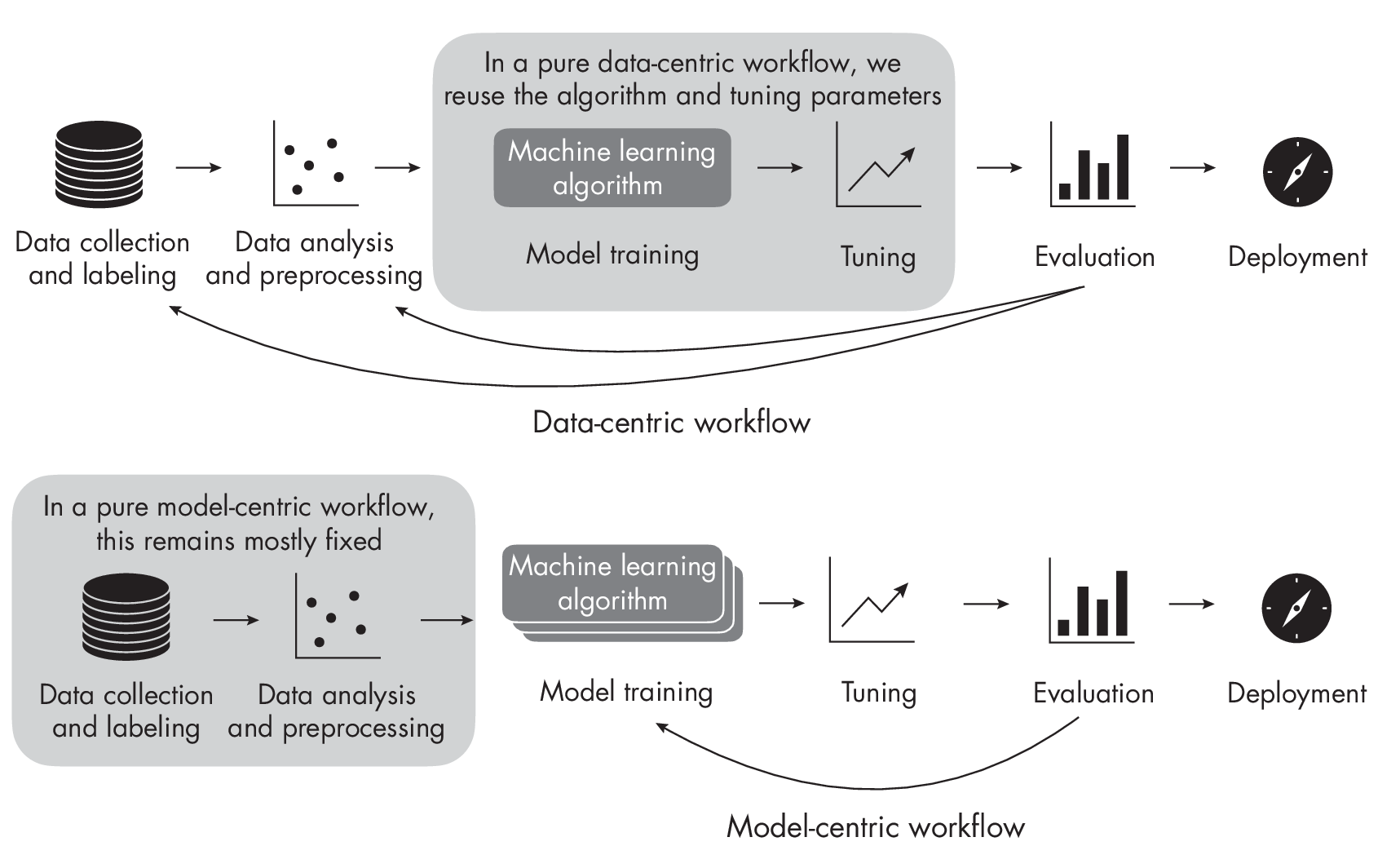
While data-centric AI is a relatively new term, the idea behind it is not. Many people I’ve spoken with say they used a data-centric approach in their projects before the term was coined. In my opinion, data-centric AI was created to make “caring about data quality” attractive again, as data collection and curation are often considered tedious or thankless. This is analogous to how the term deep learning made neural networks interesting again in the early 2010s.
Do we need to choose between data-centric and model-centric AI, or can we rely on both? In short, data-centric AI focuses on changing the data to improve performance, while model-centric approaches focus on modifying the model to improve performance. Ideally, we should use both in an applied setting where we want to get the best possible predictive performance. However, in a research setting or an exploratory stage of an applied project, working with too many variables simultaneously is messy. If we change both model and data at once, it’s hard to pinpoint which change is responsible for the improvement.
It is important to emphasize that data-centric AI is a paradigm and workflow, not a particular technique. Data-centric AI therefore implicitly includes the following:
-
Analyses and modifications of training data, from outlier removal to missing data imputation
-
Data synthesis and data augmentation techniques
-
Data labeling and label-cleaning methods
-
The classic active learning setting where a model suggests which data points to label
We consider an approach data centric if we change only the data (using the methods listed here), not the other aspects of the modeling pipeline.
In machine learning and AI, we often use the phrase “garbage in, gar- bage out,” meaning that poor-quality data will result in a poor predictive model. In other words, we cannot expect a well-performing model from a low-quality dataset.
I’ve observed a common pattern in applied academic projects that attempt to use machine learning to replace an existing methodology. Often, researchers have only a small dataset of examples (say, hundreds of training examples). Labeling data is often expensive or considered boring and thus best avoided. In these cases, the researchers spend an unreasonable amount of time trying out different machine-learning algorithms and model tuning. To resolve this issue, investing additional time or resources in labeling additional data would be worthwhile.
The main advantage of data-centric AI is that it puts the data first so that if we invest resources to create a higher-quality dataset, all modeling approaches will benefit from it downstream.
Recommendations
Taking a data-centric approach is often a good idea in an applied project where we want to improve the predictive performance to solve a particular problem. In this context, it makes sense to start with a modeling baseline and improve the dataset since it’s often more worthwhile than trying out bigger, more expensive models.
If our task is to develop a new or better methodology, such as a new neural network architecture or loss function, a model-centric approach might be a better choice. Using an established benchmark dataset without changing it makes it easier to compare the new modeling approach to previous work. Increasing the model size usually improves performance, but so does the addition of training examples. Assuming small training sets (< 2k) for classification, extractive question answering, and multiple-choice tasks, adding a hundred examples can result in the same performance gain as adding billions of parameters.
In a real-world project, alternating between data-centric and model-centric modes makes a lot of sense. Investing in data quality early on will benefit all models. Once a good dataset is available, we can begin to focus on model tuning to improve performance.
Exercises
21-1. A recent trend is the increased use of predictive analytics in healthcare. For example, suppose a healthcare provider develops an AI system that analyzes patients’ electronic health records and provides recommendations for lifestyle changes or preventive measures. For this, the provider requires patients to monitor and share their health data (such as pulse and blood pressure) daily. Is this an example of data-centric AI?
21-2. Suppose we train a ResNet-34 convolutional neural network to classify images in the CIFAR-10 and ImageNet datasets. To reduce overfitting and improve classification accuracy, we experiment with data augmentation techniques such as image rotation and cropping. Is this approach data centric?
References
-
An example of how adding more training data can benefit model performance more than an increase in model size: Yuval Kirstain et al., “A Few More Examples May Be Worth Billions of Parameters” (2021), https://arxiv.org/abs/2110.04374.
-
Cleanlab is an open source library that includes methods for improving labeling errors and data quality in computer vision and natural language processing contexts: https://github.com/cleanlab/cleanlab.
Support the Author
You can support the author in the following ways:
- Subscribe to Sebastian's Substack blog
- Purchase a copy on Amazon or No Starch Press
- Write an Amazon review