Machine Learning Q and AI
30 Essential Questions and Answers on Machine Learning and AI
By Sebastian Raschka. Free to read.
Published by No Starch Press.
Copyright © 2024-2025 by Sebastian Raschka.

Machine learning and AI are moving at a rapid pace. Researchers and practitioners are constantly struggling to keep up with the breadth of concepts and techniques. This book provides bite-sized bits of knowledge for your journey from machine learning beginner to expert, covering topics from various machine learning areas. Even experienced machine learning researchers and practitioners will encounter something new that they can add to their arsenal of techniques.
📘 Print Book:
Amazon
No Starch Press
📄 Read Online:
Full Book (Free)
Chapter 12: Fully Connected and Convolutional Layers
Under which circumstances can we replace fully connected layers with convolutional layers to perform the same computation?
Replacing fully connected layers with convolutional layers can offer advantages in terms of hardware optimization, such as by utilizing specialized hardware accelerators for convolution operations. This can be particularly relevant for edge devices.
There are exactly two scenarios in which fully connected layers and convolutional layers are equivalent: when the size of the convolutional filter is equal to the size of the receptive field and when the size of the convolutional filter is 1. As an illustration of these two scenarios, consider a fully connected layer with two input and four output units, as shown in Figure 1.1.
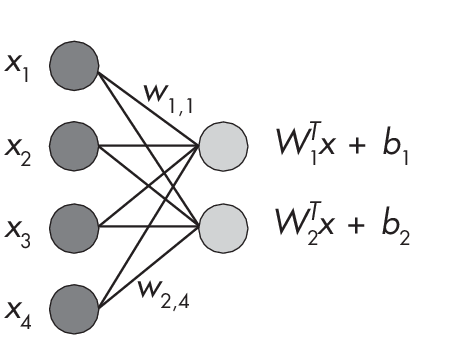
two outputs connected via
eight weight parameters
The fully connected layer in this figure consists of eight weights and two bias units. We can compute the output nodes via the following dot products:
Node 1
\[w_{1, 1} \times x_1 + w_{1, 2} \times x_2 + w_{1, 3} \times x_3 + w_{1, 4} \times x_4 + b_1\]Node 2
\[w_{2, 1} \times x_1 + w_{2, 2} \times x_2 + w_{2, 3} \times x_3 + w_{2, 4} \times x_4 + b_2\]The following two sections illustrate scenarios in which convolutional layers can be defined to produce exactly the same computation as the fully connected layer described.
When the Kernel and Input Sizes Are Equal
Let’s start with the first scenario, where the size of the convolutional filter is equal to the size of the receptive field. Recall from Chapter [ch11] how we compute a number of parameters in a convolutional kernel with one input channel and multiple output channels. We have a kernel size of 2\(\times\)2, one input channel, and two output channels. The input size is also 2\(\times\)2, a reshaped version of the four inputs depicted in Figure 1.2.
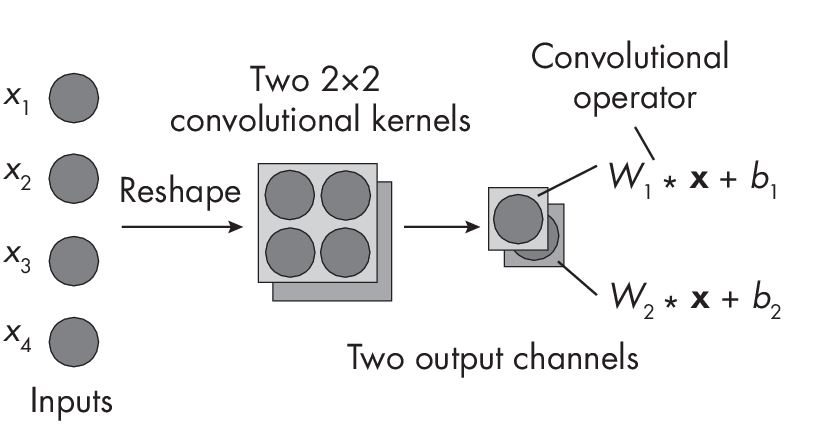
that equals the input size and two output channels
If the convolutional kernel dimensions equal the input size, as depicted in Figure 1.2, there is no sliding window mechanism in the convolutional layer. For the first output channel, we have the following set of weights:
\[{W}_1 = \begin{bmatrix} w_{1, 1} & w_{1, 2}\\ w_{1, 3} & w_{1, 4} \end{bmatrix}\]For the second output channel, we have the following set of weights:
\[{W}_2 = \begin{bmatrix} w_{2, 1} & w_{2, 2}\\ w_{2, 3} & w_{2, 4} \end{bmatrix}\]If the inputs are organized as
\[{x} = \begin{bmatrix} x_{1} & x_{2}\\ x_{3} & x_{4} \end{bmatrix}\]we calculate the first output channel as o1 = \(\sum_i\)(W1 * x)i + b1, where the convolutional operator * is equal to an element-wise multiplication. In other words, we perform an element-wise multiplication between two matrices, W1 and x, and then compute the output as the sum over these elements; this equals the dot product in the fully connected layer. Lastly, we add the bias unit. The computation for the second output channel works analogously: o2 = \(\sum_i\)(W2 * x)i + b2.
As a bonus, the supplementary materials for this book include PyTorch
code to show this equivalence with a hands-on example in the
supplementary/q12-fc-cnn-equivalence subfolder at
https://github.com/rasbt/MachineLearning-QandAI-book.
When the Kernel Size Is 1
The second scenario assumes that we reshape the input into an input “image” with \(1\times1\) dimensions where the number of “color channels” equals the number of input features, as depicted in Figure 1.3.
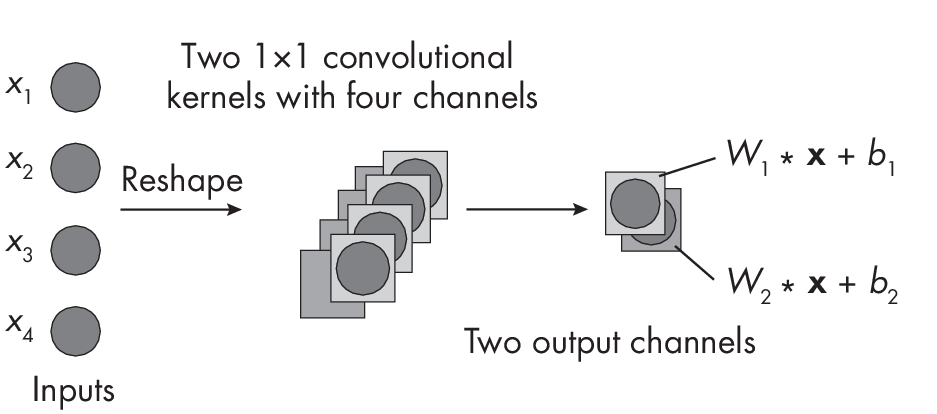
of channels if the kernel size is equal to the input size.
Each kernel consists of a stack of weights equal to the number of input channels. For instance, for the first output layer, the weights are
\[{W}_1 = [ w^{(1)}_{1} w^{(2)}_{1} w^{(3)}_{1} w^{(4)}_{1}]\]while the weights for the second channel are:
\[{W}_2 = [ w^{(1)}_{2} w^{(2)}_{2} w^{(3)}_{2} w^{(4)}_{2}]\]To get a better intuitive understanding of this computation, check out the illustrations in Chapter [ch11], which describe how to compute the parameters in a convolutional layer.
Recommendations
The fact that fully connected layers can be implemented as equivalent convolutional layers does not have immediate performance or other advantages on standard computers. However, replacing fully connected layers with convolutional layers can offer advantages in combination with developing specialized hardware accelerators for convolution operations.
Moreover, understanding the scenarios where fully connected layers are equivalent to convolutional layers aids in understanding the mechanics of these layers. It also lets us implement convolutional neural networks without any use of fully connected layers, if desired, to simplify code implementations.
Exercises
12-1. How would increasing the stride affect the equivalence discussed in this chapter?
12-2. Does padding affect the equivalence between fully connected layers and convolutional layers?
Support the Author
You can support the author in the following ways:
- Subscribe to Sebastian's Substack blog
- Purchase a copy on Amazon or No Starch Press
- Write an Amazon review