Machine Learning Q and AI
30 Essential Questions and Answers on Machine Learning and AI
By Sebastian Raschka. Free to read.
Published by No Starch Press.
Copyright © 2024-2025 by Sebastian Raschka.

Machine learning and AI are moving at a rapid pace. Researchers and practitioners are constantly struggling to keep up with the breadth of concepts and techniques. This book provides bite-sized bits of knowledge for your journey from machine learning beginner to expert, covering topics from various machine learning areas. Even experienced machine learning researchers and practitioners will encounter something new that they can add to their arsenal of techniques.
📘 Print Book:
Amazon
No Starch Press
📄 Read Online:
Full Book (Free)
Chapter 8: The Success of Transformers
What are the main factors that have contributed to the success of transformers?
In recent years, transformers have emerged as the most successful neural network architecture, particularly for various natural language processing tasks. In fact, transformers are now on the cusp of becoming state of the art for computer vision tasks as well. The success of transformers can be attributed to several key factors, including their attention mechanisms, ability to be parallelized easily, unsupervised pretraining, and high parameter counts.
The Attention Mechanism
The self-attention mechanism found in transformers is one of the key design components that make transformer-based LLMs so successful. However, transformers are not the first architecture to utilize attention mechanisms.
Attention mechanisms were first developed in the context of image recognition back in 2010, before being adopted to aid the translation of long sentences in recurrent neural networks. (Chapter [ch16] compares the attention mechanisms found in recurrent neural networks and transformers in greater detail.)
The aforementioned attention mechanism is inspired by human vision, focusing on specific parts of an image (foveal glimpses) at a time to process information hierarchically and sequentially. In contrast, the fundamental mechanism underlying transformers is a self-attention mechanism used for sequence-to-sequence tasks, such as machine translation and text generation. It allows each token in a sequence to attend to all other tokens, thus providing context-aware representations of each token.
What makes attention mechanisms so unique and useful? For the following illustration, suppose we are using an encoder network on a fixed-length representation of the input sequence or image—this can be a fully connected, convolutional, or attention-based encoder.
In a transformer, the encoder uses self-attention mechanisms to compute the importance of each input token relative to other tokens in the sequence, allowing the model to focus on relevant parts of the input sequence. Conceptually, attention mechanisms allow the transformers to attend to different parts of a sequence or image. On the surface, this sounds very similar to a fully connected layer where each input element is connected via a weight with the input element in the next layer. In attention mechanisms, the computation of the attention weights involves comparing each input element to all others. The attention weights obtained by this approach are dynamic and input dependent. In contrast, the weights of a convolutional or fully connected layer are fixed after training, as illustrated in Figure 1.1.
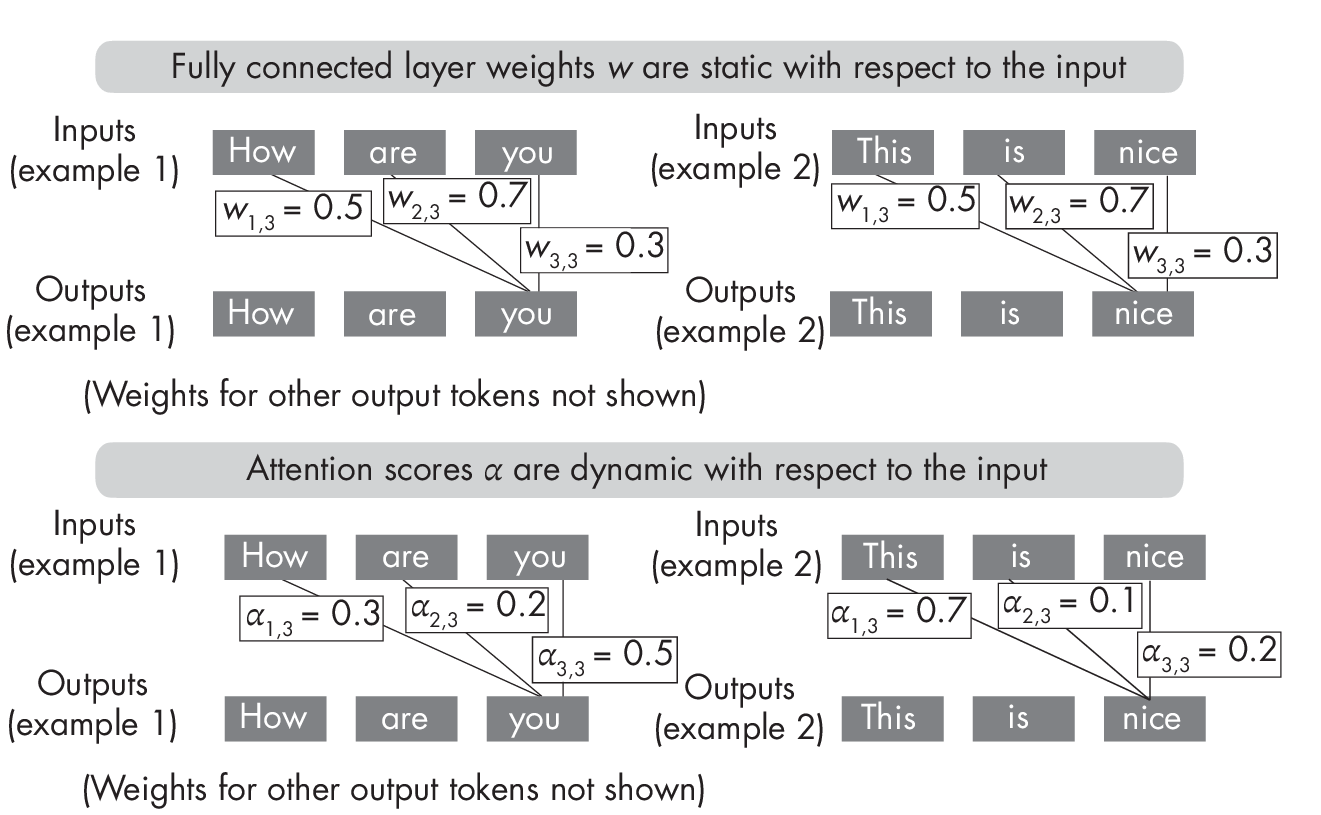
layers (top) and attention scores (bottom)
As the top part of Figure 1.1 shows, once trained, the weights of fully connected layers remain fixed regardless of the input. In contrast, as shown at the bottom, self-attention weights change depending on the inputs, even after a transformer is trained.
Attention mechanisms allow a neural network to selectively weigh the importance of different input features, so the model can focus on the mostrelevant parts of the input for a given task. This provides a contextual understanding of each word or image token, allowing for more nuanced interpretations, which is one of the aspects that can make transformers work so well.
Pretraining via Self-Supervised Learning
Pretraining transformers via self-supervised learning on large, unlabeled datasets is another key factor in the success of transformers. During pretraining, the transformer model is trained to predict missing words in a sentence or the next sentence in a document, for example. By learning to predict these missing words or the next sentence, the model is forced to learn general representations of language that can be fine-tuned for a wide range of downstream tasks.
While unsupervised pretraining has been highly effective for natural language processing tasks, its effectiveness for computer vision tasks is still an active area of research. (Refer to Chapter [ch02] for a more detailed discussion of self-supervised learning.)
Large Numbers of Parameters
One noteworthy characteristic of transformers is their large model sizes. For example, the popular 2020 GPT-3 model consists of 175 billion trainable parameters, while other transformers, such as switch transformers, have trillions of parameters.
The scale and number of trainable parameters of transformers are essential factors in their modeling performance, particularly for large-scale natural language processing tasks. For instance, linear scaling laws suggest that the training loss decreases proportionally with an increase in model size, so a doubling of the model size can halve the training loss.
This, in turn, can lead to better performance on the downstream target task. However, it is essential to scale the model size and the number of training tokens equally. This means the number of training tokens should be doubled for every doubling of model size.
Since labeled data is limited, utilizing large amounts of data during unsupervised pretraining is vital.
To summarize, large model sizes and large datasets are critical factors in transformers’ success. Additionally, using self-supervised learning, the ability to pretrain transformers is closely tied to using large model sizes and large datasets. This combination has been critical in enabling the success of transformers in a wide range of natural language processing tasks.
Easy Parallelization
Traininglargemodelsonlargedatasetsrequiresvastcomputational resources, and it’s key that the computations can be parallelized to utilize these resources.
Fortunately,transformersareeasytoparallelizesincetheytakea fixed-length sequence of word or image tokens as input. For instance, the self-attention mechanism used in most transformer architectures involves computing the weighted sum between a pair of input elements. Furthermore, these pair-wise token comparisons can be computed independently, as illustrated in Figure 1.2, making the self-attention mechanism relatively easy to parallelize across different GPU cores.
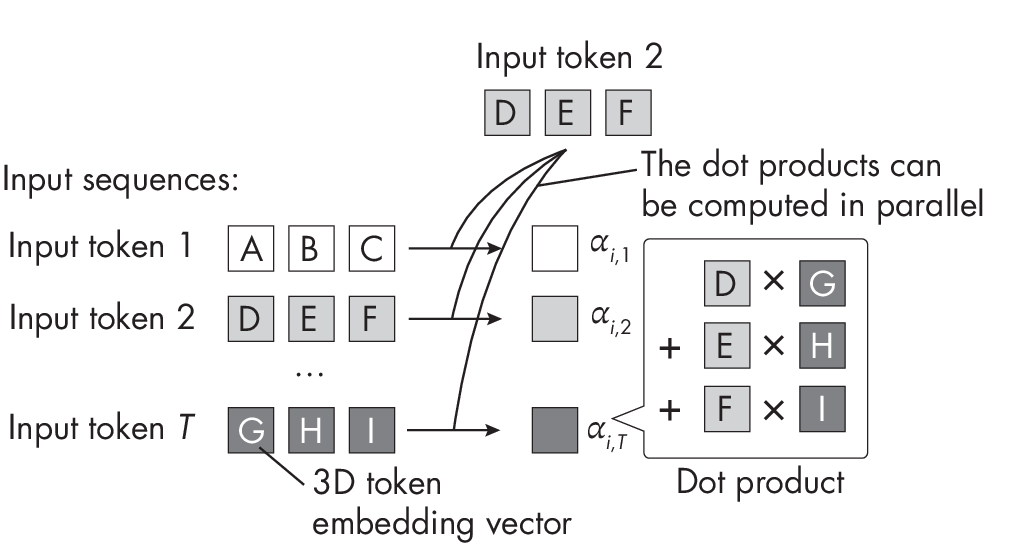
weight parameters
In addition, the individual weight matrices used in the self-attention mechanism (not shown in Figure 1.2) can be distributed across different machines for distributed and parallel computing.
Exercises
8-1. As discussed in this chapter, self-attention is easily parallelizable, yet transformers are considered computationally expensive due to self-attention. How can we explain this contradiction?
8-2. Since self-attention scores represent importance weights for the various input elements, can we consider self-attention to be a form of feature selection?
References
-
An example of an attention mechanism in the context of image rec- ognition: Hugo Larochelle and Geoffrey Hinton, “Learning to Combine Foveal Glimpses with a Third-Order Boltzmann Machine” (2010), https://dl.acm.org/doi/10.5555/2997189.2997328.
-
The paper introducing the self-attention mechanism with the original transformer architecture: Ashish Vaswani et al., “Attention Is All You Need” (2017), https://arxiv.org/abs/1706.03762.
-
Transformers can have trillions of parameters: William Fedus, Barret Zoph, and Noam Shazeer, “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity” (2021), https://arxiv.org/abs/2101.03961.
-
Linear scaling laws suggest that training loss decreases proportionally with an increase in model size: Jared Kaplan et al., “Scaling Laws for Neural Language Models” (2020), https://arxiv.org/abs/2001.08361.
-
Research suggests that in transformer-based language models, the training tokens should be doubled for every doubling of model size: Jordan Hoffmann et al., “Training Compute-Optimal Large Language Models” (2022), https://arxiv.org/abs/2203.15556.
-
Formoreabouttheweightsusedinself-attentionandcross-attention mechanisms, check out my blog post: “Understanding and Coding the Self-Attention Mechanism of Large Language Models from Scratch” at https://sebastianraschka.com/blog/2023/self-attention-from-scratch.html.
Support the Author
You can support the author in the following ways:
- Subscribe to Sebastian's Substack blog
- Purchase a copy on Amazon or No Starch Press
- Write an Amazon review