Machine Learning Q and AI
30 Essential Questions and Answers on Machine Learning and AI
By Sebastian Raschka. Free to read.
Published by No Starch Press.
Copyright © 2024-2025 by Sebastian Raschka.

Machine learning and AI are moving at a rapid pace. Researchers and practitioners are constantly struggling to keep up with the breadth of concepts and techniques. This book provides bite-sized bits of knowledge for your journey from machine learning beginner to expert, covering topics from various machine learning areas. Even experienced machine learning researchers and practitioners will encounter something new that they can add to their arsenal of techniques.
📘 Print Book:
Amazon
No Starch Press
📄 Read Online:
Full Book (Free)
Chapter 5: Reducing Overfitting with Data
Suppose we train a neural network classifier in a supervised fashion and notice that it suffers from overfitting. What are some of the common ways to reduce overfitting in neural networks through the use of altered or additional data?
Overfitting, a common problem in machine learning, occurs when a model fits the training data too closely, learning its noise and outliers rather than the underlying pattern. As a result, the model performs well on the training data but poorly on unseen or test data. While it is ideal to prevent overfitting, it’s often not possible to completely eliminate it. Instead, we aim to reduce or minimize overfitting as much as possible.
The most successful techniques for reducing overfitting revolve around collecting more high-quality labeled data. However, if collecting more labeled data is not feasible, we can augment the existing data or leverage unlabeled data for pretraining.
Common Methods
This chapter summarizes the most prominent examples of dataset-related techniques that have stood the test of time, grouping them into the following categories: collecting more data, data augmentation, and pretraining.
Collecting More Data
One of the best ways to reduce overfitting is to collect more (good-quality) data. We can plot learning curves to find out whether a given model would benefit from more data. To construct a learning curve, we train the model to different training set sizes (10 percent, 20 percent, and so on) and evaluate the trained model on the same fixed-size validation or test set. As shown in Figure 1.1, the validation accuracy increases as the training set sizes increase. This indicates that we can improve the model’s performance by collecting more data.
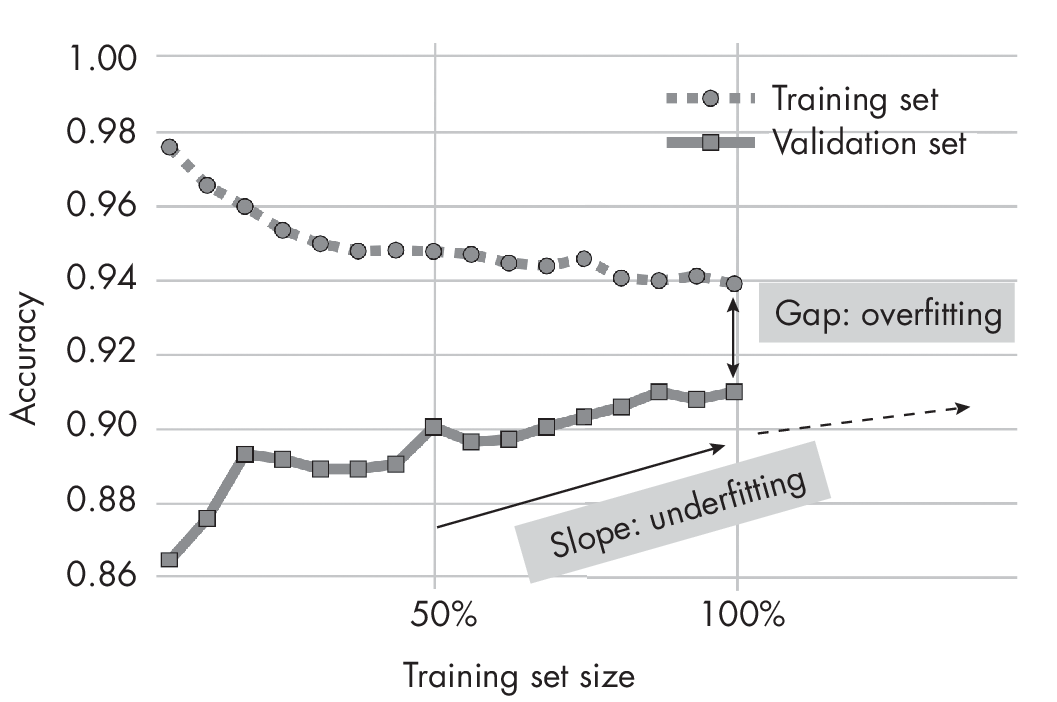
set sizes
The gap between training and validation performance indicates the degree of overfitting—the more extensive the gap, the more overfitting occurs. Conversely, the slope indicating an improvement in the validation performance suggests the model is underfitting and can benefit from more data. Typically, additional data can decrease both underfitting and overfitting.
Data Augmentation
Data augmentation refers to generating new data records or features based on existing data. It allows for the expansion of a dataset without additional data collection.
Data augmentation allows us to create different versions of the original input data, which can improve the model’s generalization performance. Why? Augmented data can help the model improve its ability to generalize, since it makes it harder to memorize spurious information via training examples or features—or, in the case of image data, exact pixel values for specific pixel locations. Figure 1.2 highlights common image data augmentation techniques, including increasing brightness, flipping, and cropping.

Data augmentation is usually standard for image data (see Figure 1.2) and text data (discussed further in Chapter [ch15]), but data augmentation methods for tabular data also exist.
Instead of collecting more data or augmenting existing data, it is also possible to generate new, synthetic data. While more common for image data and text, generating synthetic data is also possible for tabular datasets.
Pretraining
As discussed in Chapter [ch02], self-supervised learning lets us leverage large, unlabeled datasets to pretrain neural networks. This can also help reduce overfitting on the smaller target datasets.
As an alternative to self-supervised learning, traditional transfer learning on large labeled datasets is also an option. Transfer learning is most effective if the labeled dataset is closely related to the target domain. For instance, if we train a model to classify bird species, we can pretrain a network on a large, general animal classification dataset. However, if such a large animal classification dataset is unavailable, we can also pretrain the model on the relatively broad ImageNet dataset.
A dataset may be extremely small and unsuitable for supervised learning—for example, if it contains only a handful of labeled examples per class. If our classifier needs to operate in a context where the collection of additional labeled data is not feasible, we may also consider few-shot learning.
Other Methods
The previous sections covered the main approaches to using and modifying datasets to reduce overfitting. However, this is not an exhaustive list. Other common techniques include:
-
Feature engineering and normalization
-
The inclusion of adversarial examples and label or feature noise
-
Label smoothing
-
Smaller batch sizes
-
Data augmentation techniques such as Mixup, Cutout, and CutMix
The next chapter covers additional techniques to reduce overfitting from a model perspective, and it concludes by discussing which regularization techniques we should consider in practice.
Exercises
5-1. Suppose we train an XGBoost model to classify images based on manually extracted features obtained from collaborators. The dataset of labeled training examples is relatively small, but fortunately, our collaborators also have a labeled training set from an older project on a related domain. We’re considering implementing a transfer learning approach to train the XGBoost model. Is this a feasible option? If so, how could we do it? (Assume we are allowed to use only XGBoost and not another classification algorithm or model.)
5-2. Suppose we’re working on the image classification problem of implementing MNIST-based handwritten digit recognition. We’ve added a decent amount of data augmentation to try to reduce overfitting. Unfortunately, we find that the classification accuracy is much worse than it was before the augmentation. What are some potential reasons for this?
References
-
Apaperondataaugmentationfortabulardata:DerekSnow, “DeltaPy: A Framework for Tabular Data Augmentation in Py- thon” (2020), https://github.com/firmai/deltapy.
-
The paper proposing the GReaT method for generating synthetic tabular data using an auto-regressive generative large language model: Vadim Borisov et al., “Language Models Are Realistic Tabular Data Generators” (2022), https://arxiv.org/abs/2210.06280.
-
ThepaperproposingtheTabDDPMmethodforgeneratingsynthetictabulardatausingadiffusionmodel:AkimKotelnikovetal.,“TabDDPM: Modelling Tabular Data with Diffusion Models” (2022), https://arxiv.org/abs/2209.15421.
-
Scikit-learn’s user guide offers a section on preprocessing data, featuring techniques like feature scaling and normalization that can enhance your model’s performance: https://scikit-learn.org/stable/modules/preprocessing.html.
-
A survey on methods for robustly training deep models with noisy labels that explores techniques to mitigate the impact of incorrect or misleading target values: Bo Han et al., “A Survey of Label-noise Representation Learning: Past, Present and Future” (2020), https://arxiv.org/abs/2011.04406.
-
Theoretical and empirical evidence to support the idea that control- ling the ratio of batch size to learning rate in stochastic gradient descent is crucial for good modeling performance in deep neural networks: Fengxiang He, Tongliang Liu, and Dacheng Tao, “Control Batch Size and Learning Rate to Generalize Well: Theoretical and Empirical Evidence” (2019), https://dl.acm.org/doi/abs/10.5555/3454287.3454390.
-
Inclusion of adversarial examples, which are input samples designed to mislead the model, can improve prediction performance by making the model more robust: Cihang Xie et al., “Adversarial Examples Improve Image Recognition” (2019), https://arxiv.org/abs/1911.09665.
-
Label smoothing is a regularization technique that mitigates the im- pact of potentially incorrect labels in the dataset by replacing hard 0 and 1 classification targets with softened values: Rafael Müller, Simon Kornblith, and Geoffrey Hinton, “When Does Label Smoothing Help?” (2019), https://arxiv.org/abs/1906.02629.
-
Mixup, a popular method that trains neural networks on blended data pairs to improve generalization and robustness: Hongyi Zhang et al., “Mixup: Beyond Empirical Risk Minimization” (2018), https://arxiv.org/abs/1710.09412.
Support the Author
You can support the author in the following ways:
- Subscribe to Sebastian's Substack blog
- Purchase a copy on Amazon or No Starch Press
- Write an Amazon review