Machine Learning Q and AI
30 Essential Questions and Answers on Machine Learning and AI
By Sebastian Raschka. Free to read.
Published by No Starch Press.
Copyright © 2024-2025 by Sebastian Raschka.

Machine learning and AI are moving at a rapid pace. Researchers and practitioners are constantly struggling to keep up with the breadth of concepts and techniques. This book provides bite-sized bits of knowledge for your journey from machine learning beginner to expert, covering topics from various machine learning areas. Even experienced machine learning researchers and practitioners will encounter something new that they can add to their arsenal of techniques.
📘 Print Book:
Amazon
No Starch Press
📄 Read Online:
Full Book (Free)
Chapter 4: The Lottery Ticket Hypothesis
What is the lottery ticket hypothesis, and, if it holds true, how is it useful in practice?
The lottery ticket hypothesis is a concept in neural network training that posits that within a randomly initialized neural network, there exists a subnetwork (or “winning ticket”) that can, when trained separately, achieve the same accuracy on a test set as the full network after being trained for the same number of steps. This idea was first proposed by Jonathan Frankle and Michael Carbin in 2018.
This chapter illustrates the lottery hypothesis step by step, then goes over weight pruning, one of the key techniques to create smaller subnetworks as part of the lottery hypothesis methodology. Lastly, it discusses the practical implications and limitations of the hypothesis.
The Lottery Ticket Training Procedure
Figure 1.1 illustrates the training procedure for the lottery ticket hypothesis in four steps, which we’ll discuss one by one to help clarify the concept.
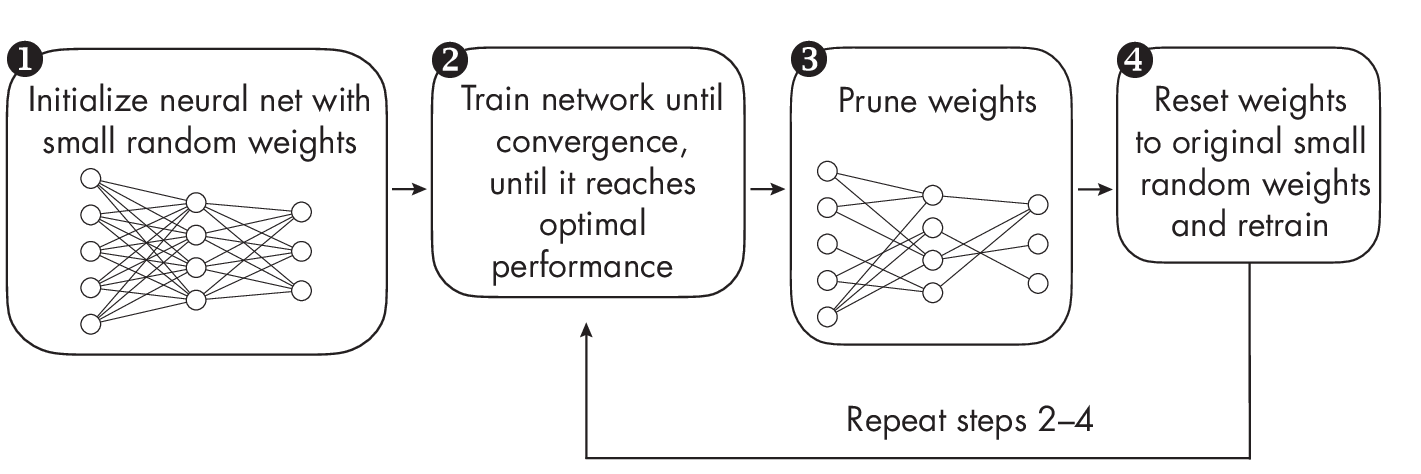
In Figure 1.1, we start with a large neural network that we train until convergence , meaning we put in our best efforts to make it perform as well as possible on a target dataset (for example, minimizing training loss and maximizing classification accuracy). This large neural network is initialized as usual using small random weights.
Next, as shown in Figure 1.1, we prune the neural network’s weight parameters , removing them from the network. We can do this by setting the weights to zero to create sparse weight matrices. Here, we can either prune individual weights, known as unstructured pruning, or prune larger “chunks” from the network, such as entire convolutional filter channels. This is known as structured pruning.
The original lottery hypothesis approach follows a concept known as iterative magnitude pruning, where the weights with the lowest magnitudes are removed in an iterative fashion. (We will revisit this concept in Chapter [ch06] when discussing techniques to reduce overfitting.)
After the pruning step, we reset the weights to the original small random values used in step 1 in Figure 1.1 and train the pruned network . It’s worth emphasizing that we do not reinitialize the pruned network with any small random weights (as is typical for iterative magnitude pruning), and instead we reuse the weights from step 1.
We then repeat the pruning steps 2 through 4 until we reach the desired network size. For example, in the original lottery ticket hypothesis paper, the authors successfully reduced the network to 10 percent of its original size without sacrificing classification accuracy. As a nice bonus, the pruned (sparse) network, referred to as the winning ticket, even demonstrated improved generalization performance compared to the original (large and dense) network.
Practical Implications and Limitations
If it’s possible to identify smaller subnetworks that have the same predictive performance as their up-to-10-times-larger counterparts, this can have significant implications for both neural training and inference. Given the ever-growing size of modern neural network architectures, this can help cut training costs and infrastructure.
Sound too good to be true? Maybe. If winning tickets can be identified efficiently, this would be very useful in practice. However, at the time of writing, there is no way to find the winning tickets without training the original network. Including the pruning steps would make this even more expensive than a regular training procedure. Moreover, after the publication of the original paper, researchers found that the original weight initialization may not work to find winning tickets for larger-scale networks, and additional experimentation with the initial weights of the pruned networks is required.
The good news is that winning tickets do exist. Even if it’s currently not possible to identify them without training their larger neural network counterparts, they can be used for more efficient inference after training.
Exercises
4-1. Suppose we’re trying out the lottery ticket hypothesis approach and find that the performance of the subnetwork is not very good (compared to the original network). What next steps might we try?
4-2. The simplicity and efficiency of the rectified linear unit (ReLU) activation function have made it one of the most popular activation functions in neural network training, particularly in deep learning, where it helps to mitigate problems like the vanishing gradient. The ReLU activation function is defined by the mathematical expression max(0, x). This means that if the input x is positive, the function returns x, but if the input is negative or 0, the function returns 0. How is the lottery ticket hypothesis related to training a neural network with ReLU activation functions?
References
-
The paper proposing the lottery ticket hypothesis: Jonathan Frankle and Michael Carbin, “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks” (2018), https://arxiv.org/abs/1803.03635.
-
The paper proposing structured pruning for removing larger parts, such as entire convolutional filters, from a network: Hao Li et al., “Pruning Filters for Efficient ConvNets” (2016), https://arxiv.org/abs/1608.08710.
-
Follow-up work on the lottery hypothesis, showing that the original weight initialization may not work to find winning tickets for larger-scale networks, and additional experimentation with the initial weights of the pruned networks is required: Jonathan Frankle et al., “Linear Mode Connectivity and the Lottery Ticket Hypothesis” (2019), https://arxiv.org/abs/1912.05671.
-
An improved lottery ticket hypothesis algorithm that finds smaller networks that match the performance of a larger network exactly: Vivek Ramanujan et al., “What’s Hidden in a Randomly Weighted Neural Network?” (2020), https://arxiv.org/abs/1911.13299.
Support the Author
You can support the author in the following ways:
- Subscribe to Sebastian's Substack blog
- Purchase a copy on Amazon or No Starch Press
- Write an Amazon review