From Random Forests to RLVR: A Short History of ML/AI Hello Worlds
Two years ago, I posted a list of “Hello World” examples for machine learning and AI on social. Here, the “Hello World” means beginner-friendly examples to showcase a method.
I set a biennial calendar alert to revisit and append to it. I was thinking pretty hard about what a 2025 example could look like. So, here is a short post with the updated list and some explanations for more context.
- 2013: RandomForestClassifier on Iris
- 2015: XGBoost on Titanic
- 2017: MLPs on MNIST
- 2019: AlexNet on CIFAR-10
- 2021: DistilBERT on IMDb movie reviews
- 2023: Llama 2 with LoRA on Alpaca 50k
- 2025: Qwen3 with RLVR on MATH-500
Let’s go through them one by one.
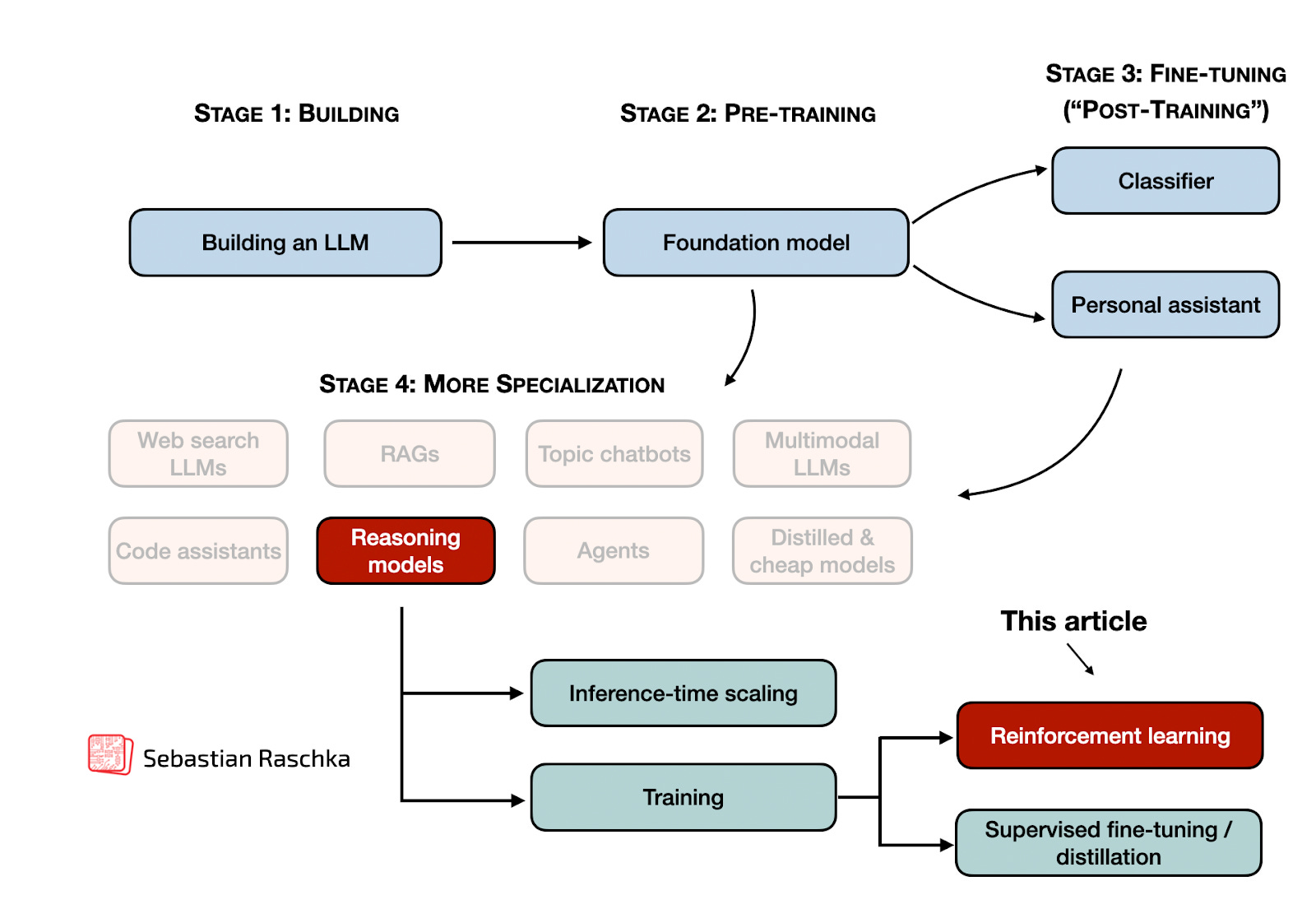
2013: RandomForestClassifier on Iris
Note that the methods in the list lag a few years behind. For instance, random forests were introduced in 2001. But based on what I remember from back then, they didn’t become super popular and mainstream until 2013ish, after they were added to scikit-learn in 2012, which was the main machine learning library back then.
- Code example from Python Machine Learning
2015: XGBoost on Titanic
XGBoost was first released in 2014, and I remember that it became super popular in 2015 in the context of Kaggle competitions (and there was the popular Titanic dataset competition everyone started with).
- Code example on Kaggle
2017: MLPs on MNIST
Multilayer perceptrons (MLPs) have been around for a looong time. They became somewhat practical in the 1980s and 90s after the 1986 backpropagation paper, but they weren’t super popular. I remember that the early 2010s were still dominated by random forests, support vector machines, and gradient boosting (specifically XGBoost). And in the meantime, non-neural network-based methods remained popular in computer vision. However, with the initial release of TensorFlow in 2015, and TensorFlow 1.0 in 2017, MLPs and neural networks in general really picked up steam around that time.
- Code example from my deep learning notebook collection
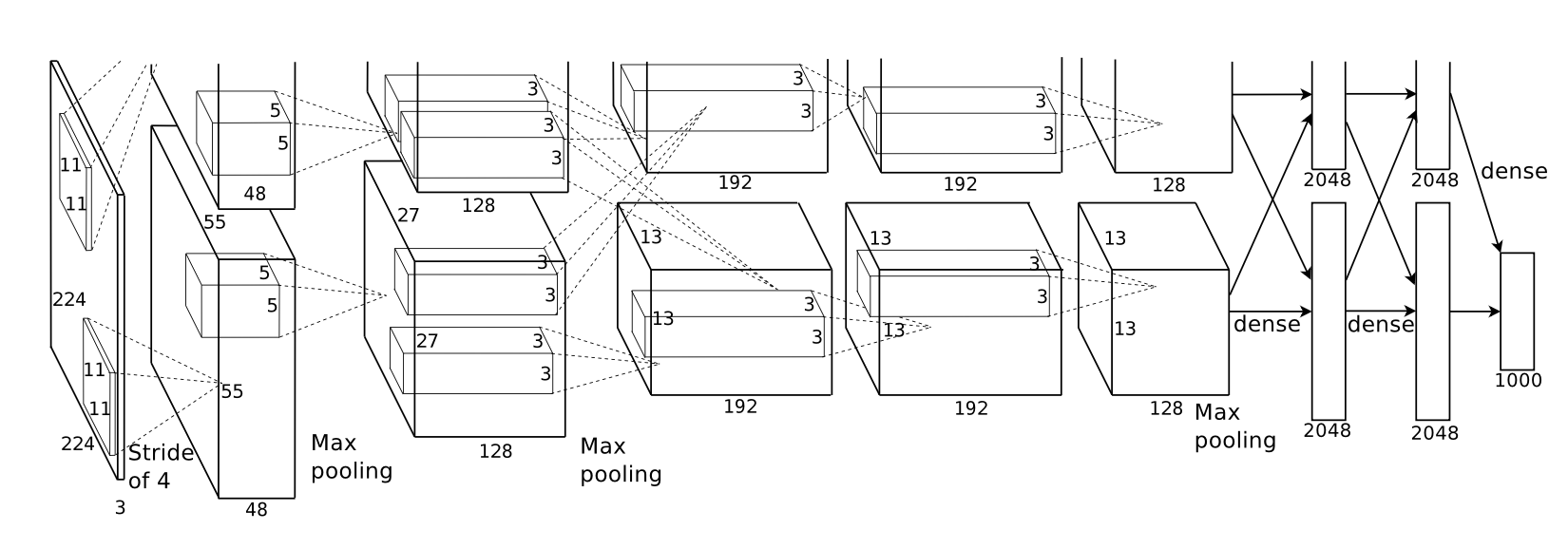
2019: AlexNet on CIFAR-10
AlexNet should probably come earlier in this list, since it was introduced in 2012 via the ImageNet Classification with Deep Convolutional Neural Networks paper. However, it also didn’t become super popular until PyTorch and TensorFlow 1.0 were released in 2017. Most people were still using Caffe at the time, but there was also a shift to TensorFlow for computer vision.
Still, since it required GPUs to do any meaningful work with convolutional neural networks, which CUDA and cuDNN made more accessible, I think that putting it after the “2017 MPLPs on MNIST” example seems fair. (Also, ImageNet was way too large and expensive for most people at the time, so CIFAR-10 and CIFAR-100 were popular beginner datasets.)
- Code example from my deep learning notebook collection
2021: DistilBERT on IMDb movie reviews
DistilBERT on the IMDb movie reviews sentiment classification dataset gets us to the era where language models started to pick up steam. Sure, the Transformer architecture was introduced in 2017, BERT in 2018, and DistilBERT in 2019, but it still took a few years for it to become popular.
- Code example from my deep learning notebook collection
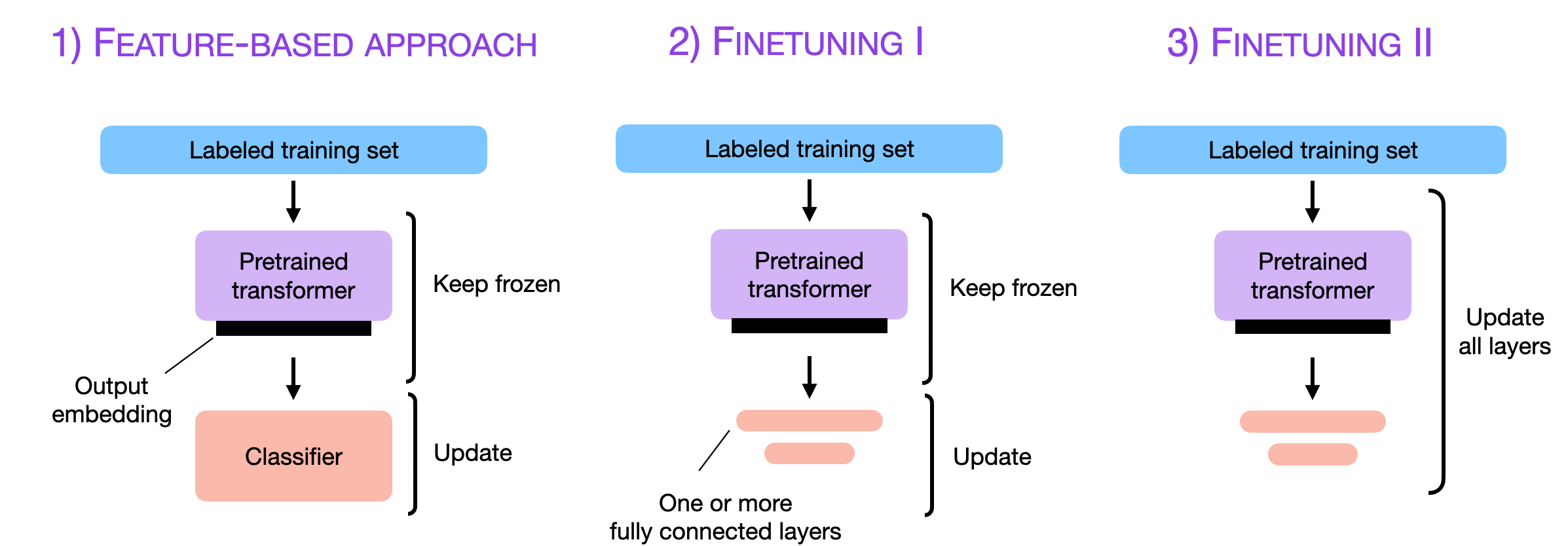
2023: Llama 2 with LoRA on Alpaca 50k
2023 was the year after the launch of ChatGPT, and LLMs picked up steam very quickly. There was still a big barrier due to the cost of training or fine-tuning LLMs, but the combination of LoRA, Llama 1 and 2, and the Alpaca dataset made LLMs suddenly much more accessible, and there was a huge boom in instruction fine-tuning.
- Code example by Radek Osmulski on GitHub
2025: Qwen3 with RLVR on MATH-500
Now, this year is the year of reasoning models and reinforcement learning with verifiable rewards (RLVR), which was kick-started with some hype around the first OpenAI o1 release in 2024, but then really picked up steam in January 2025 with the release of DeepSeek R1.
This year, Qwen3 models have also become super popular, and they come in many sizes from 0.6B to 235B. However, training a reasoning model with RLVR is still not trivial, even for the smallest model on the training portion of the MATH-500 dataset (that’s essentially the topic of my new book).
However, proprietary API services exist to showcase to a beginner what RLVR is, so it may be a good “Hello World” example and intro to AI (before the beginners want to dive into further details.)
- Code example from the Tinker API Cookbook (I am not affiliated with this company but think this is a good, fast intro example); from-scratch implementation to be added soon in my reasoning from scratch book.